
로지스틱 회귀는 분류(Classification)를 수행하는 알고리즘으로, 이진 분류 문제(0 또는 1)를 해결할 때 사용된다.
예를 들어, 고객이 이메일을 클릭했는지 여부를 확인하거나, 스팸 메일 여부를 분류하는 데 사용할 수 있다.
결과값은 0과 1 사이의 확률로 출력되며,
일반적으로 0.5를 기준으로 데이터를 나눈다.
로지스틱 회귀는 분류를 위해 S자(Sigmoid) 형태의 함수를 사용해 확률값을 계산한다.




범위가 다 다르다 그래서 범위를 특정범위로 만들어주어야한다.
그래야 각컬럼 행별 비교가 가능하다.
그래야 학습이 잘된다 각 변수(특징)의 값이 서로 다른 범위를 가지면, 모델이 특정 변수에 과도하게 영향을 받을 수 있다.
따라서, 변수의 범위를 동일하게 맞춰주는 작업(스케일링)이 필요하다
이렇게 해야 각 컬럼 간 비교가 가능해지고, 모델이 데이터를 균형 있게 학습할 수 있다.
이 과정은 학습 성능을 높이고, 모델의 예측 정확도를 향상시키는 데 중요한 역할을 한다.

표준화 정규화
from sklearn.preprocessing import MinMaxScaler ,StandardScaler
y는 이미 0과 1로 변환되어 있으므로 추가적인 스케일링이 필요 없다.
반면, X 데이터는 변수별로 값의 범위가 다를 수 있으므로,
X 데이터에만 표준화 또는 정규화를 적용해 변수 간의 스케일 차이를 맞추는 것이 중요하다.
이를 통해 모델 학습이 더 효율적이고 정확하게 이루어진다.
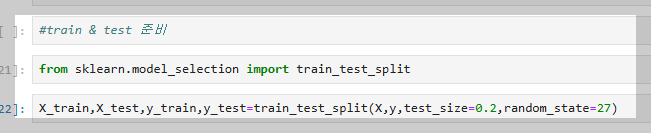
모델 학습을 위해 데이터를 트레인/테스트 데이터로 분리하고, 분류 모델의 변수 이름은 classifier로 설정하는 것이 일반적이다. 이는 코드의 가독성을 높이고, 모델의 역할을 직관적으로 나타내기 위한 국룰이다.
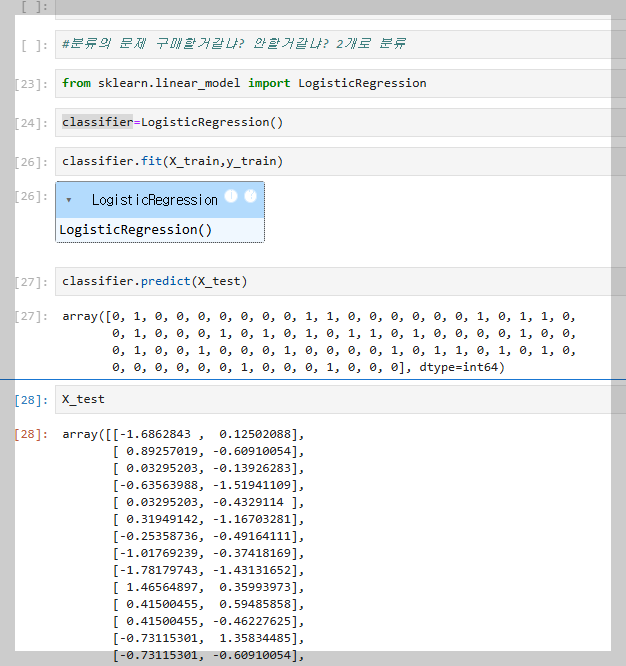
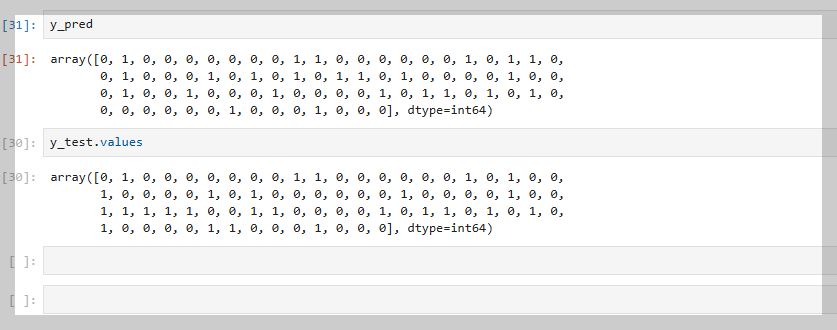

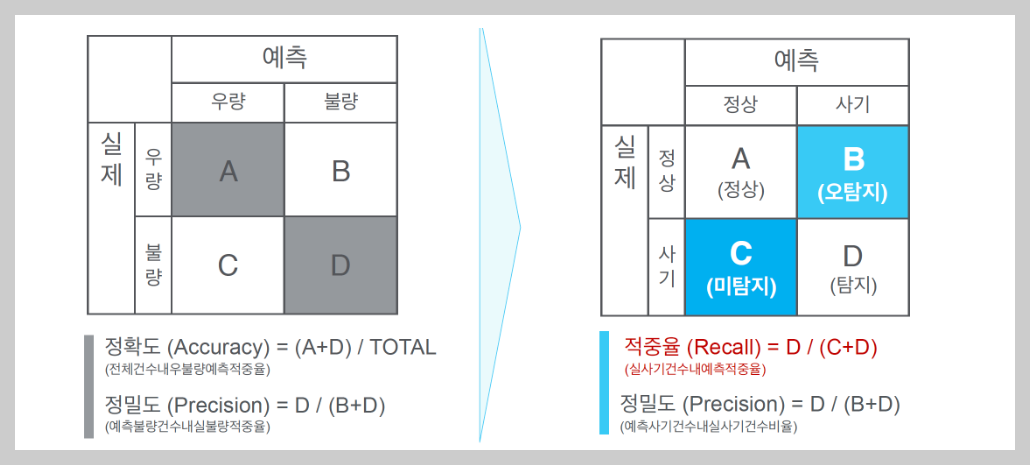
구매 여부를 예측하는 분류 문제에서는 MSE(평균 제곱 오차)가 아닌, Confusion Matrix을 사용하여 모델 성능을 평가한다. 혼동 행렬은 예측 결과를 TP(참 양성), FP(거짓 양성), TN(참 음성), FN(거짓 음성)으로 구분하며, 이를 통해 분류 모델의 정확도와 오류를 직관적으로 확인할 수 있다.
혼동 행렬에는 총 네 가지 지표가 포함된다.
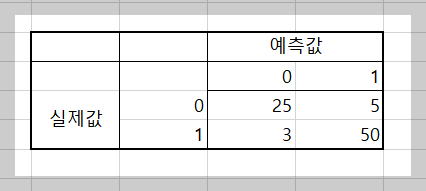
컨퓨전 매트릭스(confusion matrix)는 로지스틱 회귀를 비롯한 분류 모델의 성능을 평가하기 위해 사용된다. 위 그림은 컨퓨전 매트릭스의 예시로, 예측 값과 실제 값을 기준으로 네 가지 경우의 수를 나타낸다.
컨퓨전 매트릭스는 다음과 같은 구조를 가진다
- 왼쪽에서 오른쪽 대각선 (True Positives와 True Negatives): 모델이 올바르게 예측한 값이다. 이 값들은 모델의 정확도를 계산하는 데 중요한 요소가 된다.
- 오른쪽에서 왼쪽 대각선 (False Positives와 False Negatives): 모델이 틀리게 예측한 값이다.
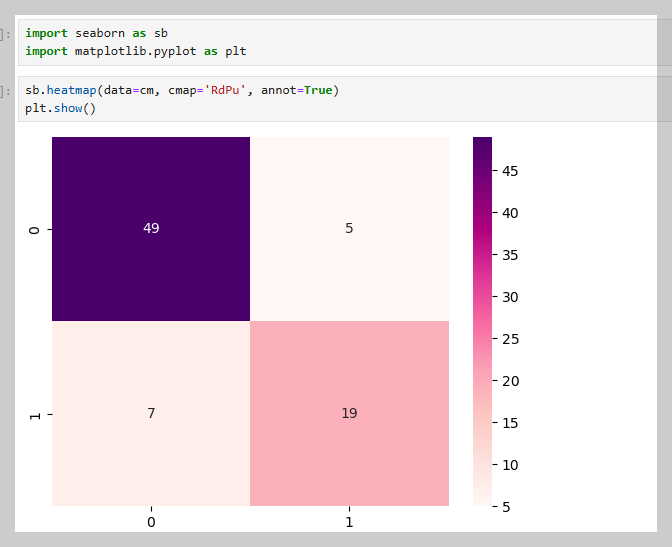
분류 모델의 예측 결과와 실제 값을 비교하여 컨퓨전 매트릭스를 생성 하는 함수
from sklearn.metrics import confusion_matrix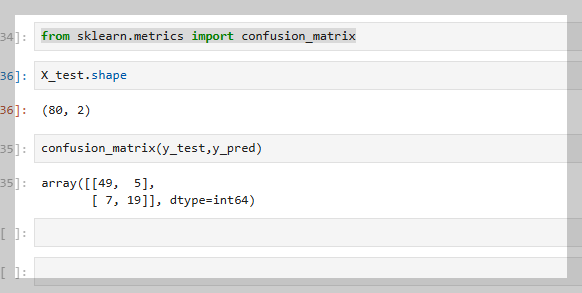
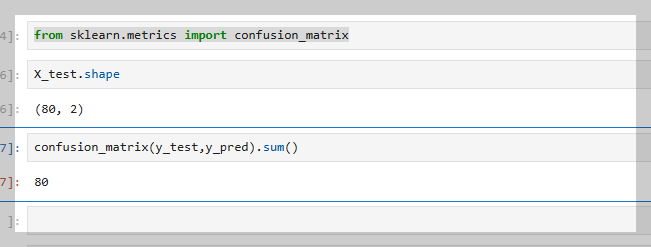
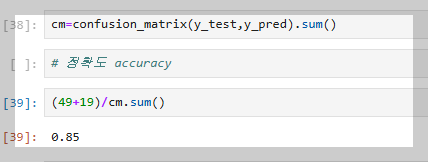
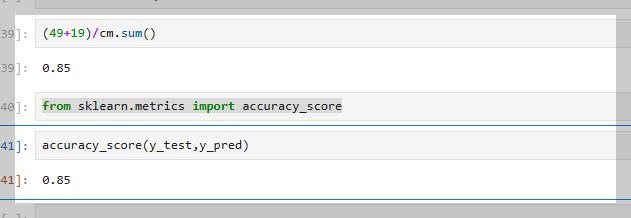
정확도 측정 함수
from sklearn.metrics import accuracy_score
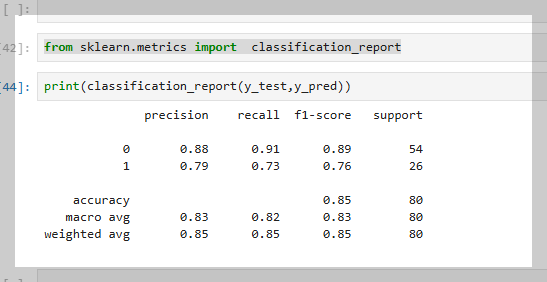
분류 모델의 성능 평가 지표(정확도, 정밀도, 재현율, F1 점수 등)를 요약한 보고서를 생성하는 함수
from sklearn.metrics import classification_report
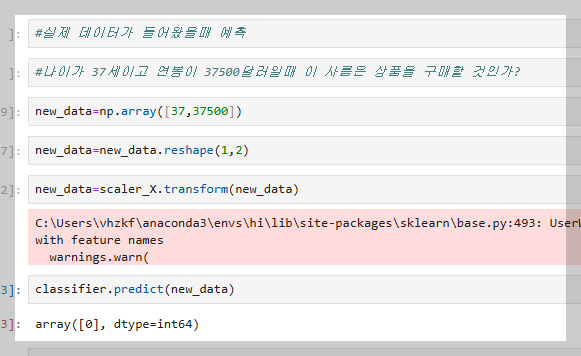
로지스틱 회귀 모델에서는 피처 스케일링(feature scaling)이 필수적이다.
이는 데이터의 스케일 차이를 조정하여 학습 속도를 개선하고, 잘못된 결과를 방지하는 과정이다.
특히, 경사하강법을 사용하는 로지스틱 회귀에서 스케일링을 하지 않으면 학습이 비효율적이거나 값이 왜곡될 수 있다. 따라서 모델 구현 및 서비스화 시 반드시 포함해야 하는 중요한 단계이다.
C2에서 모델을 실행하려면, 현재 Jupyter Notebook에서 작업한 데이터를 파일로 저장해야 한다. 특히 피처 스케일링(feature scaling)을 적용한 데이터를 저장할 경우, 스케일링 전 원본 데이터와 스케일링 후 데이터 두 개의 파일을 저장해야 한다.
원본 데이터와 스케일링된 데이터를 각각 저장하면, EC2 환경에서 안정적이고 일관된 데이터 처리와 모델 학습이 가능하다.
'Spring Boot JPA > 실습' 카테고리의 다른 글
| 박스오피스 OPEN API 실습과 배포 (0) | 2025.01.13 |
|---|---|
| YouTube검색 활용한 OPEN API 서버 개발 실습 (0) | 2025.01.10 |
| 여행코스 공유 플랫폼 JPA (0) | 2025.01.09 |
| JPA Join과 Config 설정으로 데이터베이스 관계 정리2 (0) | 2025.01.08 |
| JPA Join과 Config 설정으로 데이터베이스 관계 정리 (0) | 2025.01.07 |