from flask_restful import Resource
from flask import request
from mysql_connection import get_connection
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
class RecommendResource(Resource) :
def get(self):
user_id = request.args.get('user_id')
user_id = int(user_id)
size = request.args.get('size')
size = int(size)
review_cnt = request.args.get('review_cnt')
review_cnt = int(review_cnt)
connection = get_connection()
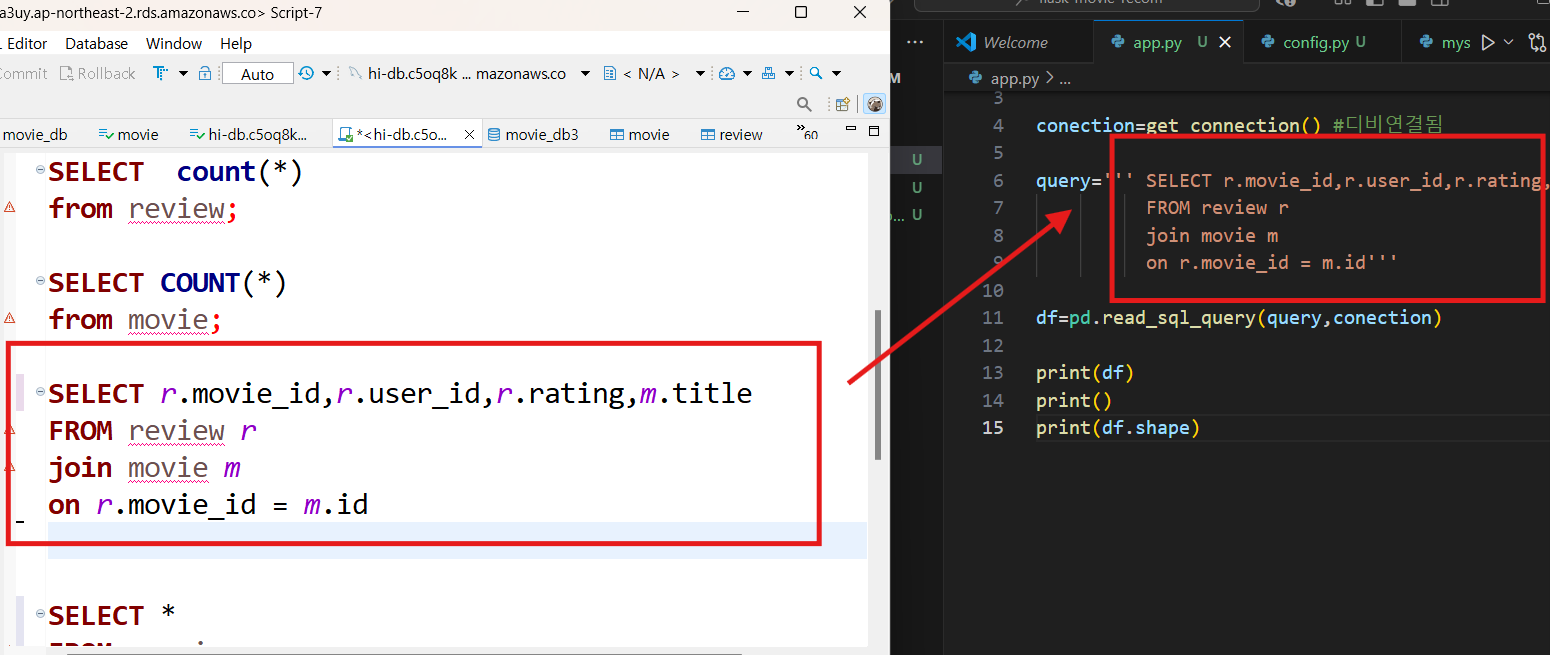
query = '''select movie_id, user_id, rating
from review;'''
review_df = pd.read_sql_query(query, connection)
query = '''select id as movie_id, title
from movie;'''
title_df = pd.read_sql_query(query, connection)
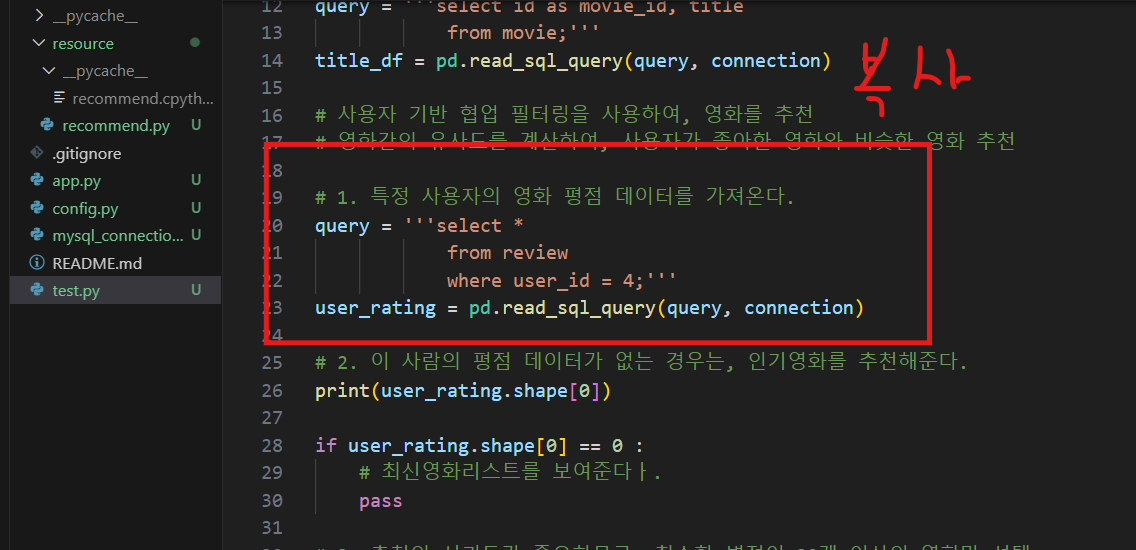
# 1. 특정 사용자의 영화 평점 데이터를 가져온다.
query = f'''select *
from review
where user_id = {user_id};'''
user_rating = pd.read_sql_query(query, connection)
print(user_rating)
# 2. 이 사람의 평점 데이터가 없는 경우는, 인기영화를 추천해준다.
if user_rating.shape[0] == 0 :
# 최신영화리스트를 보여준다ㅏ.
popular_movies = self.get_popular_movies(review_df, title_df)
return {"count" : popular_movies.shape[0],
"items" : popular_movies.to_dict('records') } , 200
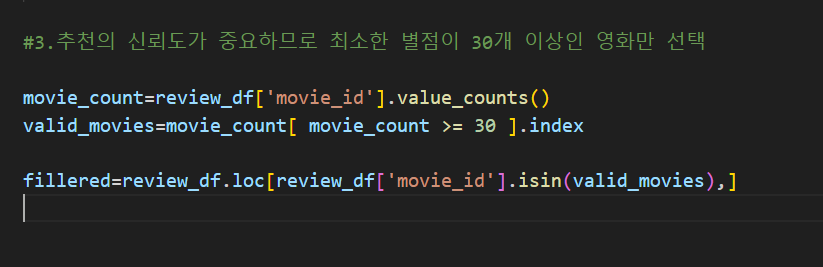
# 3. 추천의 신뢰도가 중요하므로, 최소한 별점이 30개 이상인 영화만 선택
movie_count = review_df['movie_id'].value_counts()
valid_movies = movie_count[ movie_count >= review_cnt ].index
filtered_reviews = review_df.loc[ review_df['movie_id'].isin(valid_movies) , ]
# 4. 영화-사용자-별점 데이터프레임이 필요하다.
# 인덱스에 영화아이디, 컬럼에 유저아이디, 밸류부분에 별점
movie_user_matrix = filtered_reviews.pivot_table(index= 'movie_id',
columns='user_id',
values='rating' ).fillna(0)
# 5. 유저간 유사도 계산
# - 코사인 유사도 : 별점 패턴의 방향성을 비교해서 취향의 유사도 측정.
# 두개의 벡터간의 각도를 코사인값으로 측정
# 범위 : -1 ~ 1 사이의 값
# 1 : 완벽히 유사한 패턴
# 0 : 관계 없음
# -1 : 완벽히 반대되는 패턴
item_similarity = cosine_similarity(movie_user_matrix)
item_similarity_df = pd.DataFrame(
data=item_similarity,
index=movie_user_matrix.index,
columns=movie_user_matrix.index
)
# 6. 유저가 평가한 영화 중에서, 리뷰갯수가 30개 이상인 영화만 가져온다.
watched_movies = user_rating.loc[ user_rating['movie_id'].isin(valid_movies) , ]
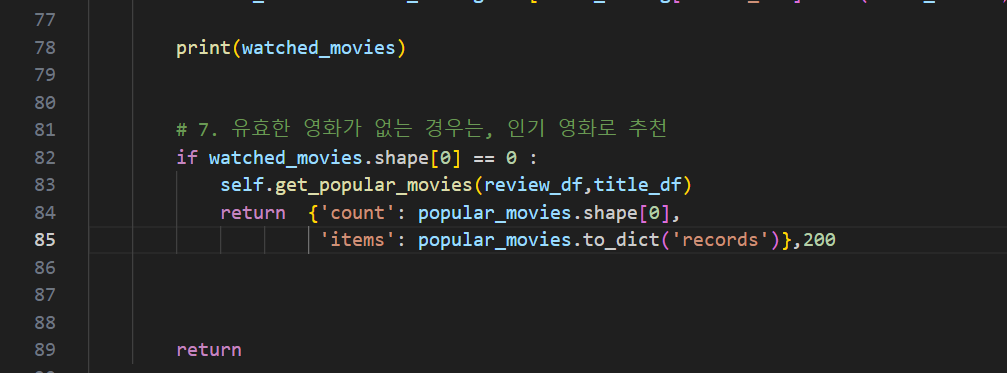
# 7. 유효한 영화가 없는 경우는, 인기 영화로 추천
if watched_movies.shape[0] == 0 :
popular_movies = self.get_popular_movies(review_df, title_df)
return {"count" : popular_movies.shape[0],
"items" : popular_movies.to_dict('records')}, 200
# 8. 추천영화를 계산하기 위해서, 빈 데이터프레임을 만든다.
recommendation_df = pd.DataFrame(index= movie_user_matrix.index)
recommendation_df['similarity_score'] = 0
# 9. 추천 점수 계산
for movie_id in watched_movies['movie_id'].tolist() :
rating = user_rating.loc[ user_rating['movie_id'] == movie_id , ]['rating'].iloc[0]
recommendation_df['similarity_score'] += item_similarity_df[movie_id] * rating
# 10. 부가적으로 보낼 데이터를 계산
# 별점 평균과 리뷰갯수를 계산.
movie_stats = filtered_reviews.groupby('movie_id')['rating'].agg( ['mean', 'count'] ).reset_index()
movie_stats.columns = ['movie_id','average_rating', 'rating_count']
# 11. 추천 데이터프레임에 합친다.
recommendation_df.reset_index(inplace=True)
recommendation_df = pd.merge(recommendation_df, movie_stats, on='movie_id', how='left' )
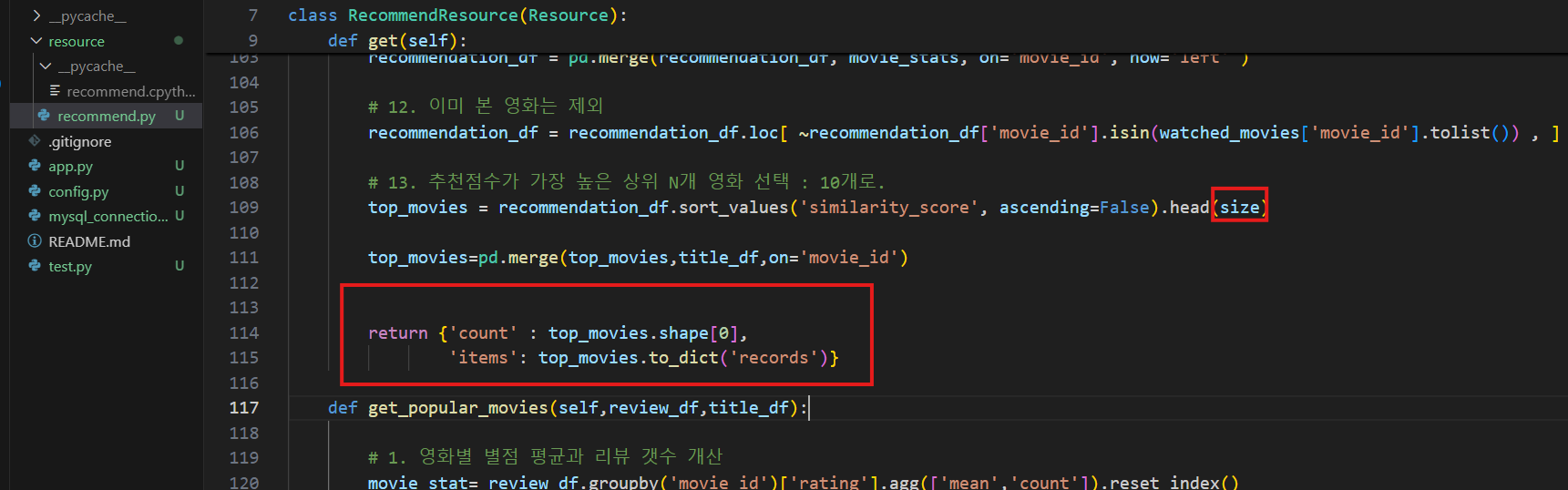
# 12. 이미 본 영화는 제외
recommendation_df = recommendation_df.loc[ ~recommendation_df['movie_id'].isin(watched_movies['movie_id'].tolist()) , ]
# 13. 추천점수가 가장 높은 상위 N개 영화 선택 : 10개로.
top_movies = recommendation_df.sort_values('similarity_score', ascending=False).head(size)
top_movies = pd.merge(top_movies, title_df, on='movie_id')
top_movies.drop('similarity_score', axis=1, inplace=True)
return {"count" : top_movies.shape[0],
"items" : top_movies.to_dict('records')}
def get_popular_movies(self, review_df, title_df) :
# 1. 영화별 별점 평균과 리뷰갯수 계산.
movie_stat = review_df.groupby('movie_id')['rating'].agg(['mean', 'count']).reset_index()
# 2. 리뷰갯수 30개 이상인 영화만 선택
popular_movies = movie_stat.loc[ movie_stat['count'] >= 30 , ]
# 3. 별점 평균이 높은 순으로 정렬
popular_movies = popular_movies.sort_values('mean', ascending=False).head(10)
popular_movies = pd.merge(popular_movies, title_df, on='movie_id')
popular_movies.columns = ['movie_id', 'average_rating', 'rating_count', 'title']
return popular_movies