


일차원 데이처이다 앞에 노란 상자는 인덱스이다
용어 필수 암기 판다스의 1차원 데이터는 Series(시리즈)라고 한다
시리즈의 왼쪽 위 노란상자부분이 인덱스라한다 사람용 인덱스 그리고 노랑 상자 옆부분 오른쪽을 values라고 부른다.


이렇게 1차원 판다스 완성


판다스(Pandas)는 NumPy의 확장 버전으로,
데이터를 더 효율적으로 다루고 분석할 수 있도록 설계된 라이브러리이다.
데이터 분석과 처리에 강력한 기능을 제공하여,
구조화된 데이터를 쉽게 관리하고 분석할 수 있게 해준다.



가저와라 의 [ ]는 초록색 리스트여러개니깐 노란색으로 리스트
그리고 데이터를 가져올때 숫자로 생각안해도 사람친화적이라 눈에 보이는 데로 써도 괜찮다

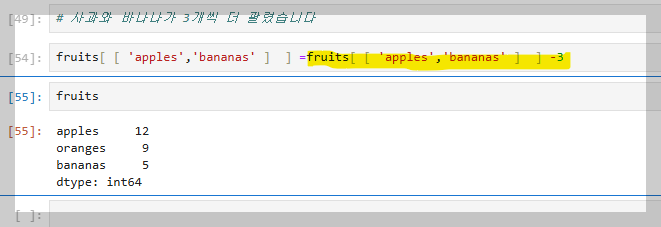
위 처럼 연산도 직접적으로 하면된다. 이것이 판다스의 장점이다



numpy 에 왼쪽과 위에다가 인덱스와 컬럼을 붙여 놓은것
데이터프레임의 왼쪽을 인덱스 라고 하고 윗부분을 컬럼이라고 한다.
NaN 데이터가 없다는 뜻(=null)
데이타프레임은 판다스거이다
그리고 데이타프레임은 df라는 변수명으로 시작되는 경우가 대다수이다


CSV는 Comma Separated Values의 약자로, 데이터를 콤마로 구분하여 저장하는 파일 형식이다.
- 첫 번째 행: 컬럼명(데이터의 필드 이름).
- 두 번째 행부터: 실제 데이터 값이 저장된다.
- 구분자: 기본적으로 콤마(,)를 사용하여 각 데이터를 구분한다.

./ (상위 폴더로 가라) /데이타폴더/원하는폴더
../는 상위 폴더로 이동을 의미한다.
- 현재 폴더에서 한 단계 상위 폴더로 이동.
- 그 안에 있는 데이터폴더로 이동.
- 이어서 원하는폴더로 이동하는 경로를 나타낸다.
주로 파일이나 폴더 경로를 지정할 때 사용된다.


판다스의 2차원 데이터인 데이터 프레임에서 데이터를 억세스 하는 방법


1. 컬럼의 값을 가져오는 방법 => 변수명에 바로 대괄호쓰고 컬럼명을 쓴다


2.행과 열의 정보로 데이터를 가져오는 방법
-사람용 인덱스와 컬럼명으로 데이터 억세스(가져오는)방법
변수명.lic[ , ]
이건 판다스만 가능하다

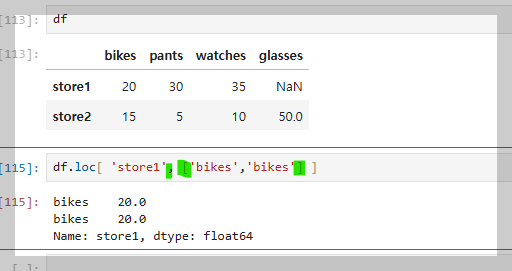
스토어 원에 바이크부터 와치까지 가져오는 방법은 노란색을 이용해서
특정 부분끼리 만가져오고 싶으면 초록 부분 처럼 하면된다


- 행과 열로 데이터를 가져오되 컴퓨가 매기는 인덱스와 컴퓨터가 매기는 컬럼정보를 가져오는 방 법
변수명.loc[ , ]
변수명.iloc[ , ]


결과 값은 같지만 사람용인 문자로 찾느냐 컴터용 숫자로 찾느냐의 차이다




새로운컬럼을 만들자(데이터가공) 열을 추가하는 방법
더하는 것도 바로 가져와 직접더해주면된다. 파이썬은 알아서 다한다.

판다스에서 데이터를 합치려면 concat() 함수를 사용하면 된다.
이를 통해 여러 데이터프레임이나 시리즈를 행(row) 또는 열(column) 기준으로 손쉽게 결합할 수 있다.

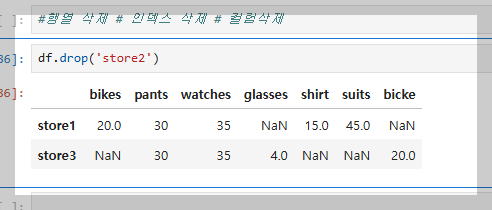
삭제하고 싶으면 df.drop(삭제하고 싶은 인데스나 컬럼명) 을 써주면된다
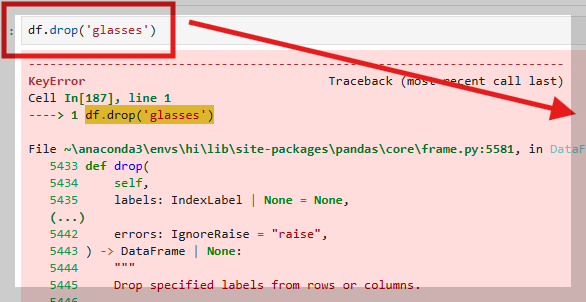


글래시스는 컬럼이므로 **df.drop()**에서 삭제하려면 **축 정보(axis)**를 추가로 지정해야 한다.
(항상 안보여줘야 저장이기에 지금은 저장되지 않았다 그래서 다시 df찍으면 삭제되지 않은 원본이 나타난다)
삭제역시 여러개 삭제 하기 위해서는 리스트를 활용하면된다


딕셔너리 형태로 키-값을 작성하면 데이터프레임의 인덱스명을 변경할 수 있다.
이때, 키는 기존 인덱스명, 값은 새로운 인덱스명으로 지정된다.

네임 컬럼을 인덱스로 설정하려면 **set_index()**를 사용하면 된다. 이를 통해 원하는 컬럼을 데이터프레임의 인덱스로 설정할 수 있다.

그리고 원래 인덱스를 삭제 하고 싶으면 파라미터 자리에 drop=True를 써주면된다
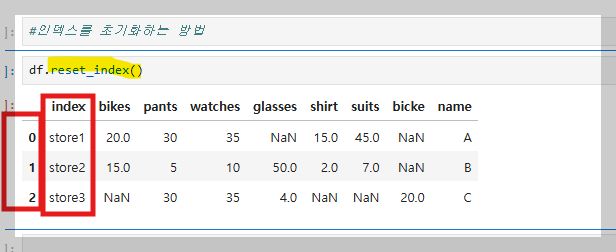
인덱스를 초기화하려면 **reset_index()**를 사용하면 된다.
- 기존 인덱스는 컬럼으로 이동하며, 새로운 인덱스는 초기값으로 설정된다.
- 기존 인덱스를 삭제하려면 **drop=True**를 파라미터로 추가하면 된다.

컬럼 순서를 변경하려면 리스트로 원하는 순서를 작성한 후,
이를 데이터프레임에 적용하면 된다.
SQL에서 컬럼을 정렬하듯, 리스트에 컬럼명을 원하는 순서대로 나열하여 사용한다.



비어있니 물어보는게 .isna() 데이터가 있니? .notna()


중복데이터 삭제할떄는 drop_dulicatres 이고
nan 삭제는 dropna 로 쓴다 na는 이처럼 전용함수가 있
df.dropna()는 결측값(NA 또는 NaN)이 있는 행이나 열을 삭제하는 데 사용된다.
- 기본 동작: 결측값이 포함된 모든 행(row)을 삭제한다.
- 파라미터 옵션:
- axis=0: 결측값이 있는 행 삭제(기본값).
- axis=1: 결측값이 있는 열 삭제.
- inplace=True: 원본 데이터프레임에 변경 사항 적용.
- how='all': 모든 값이 결측값인 경우에만 삭제.
- thresh=n: 결측값이 아닌 데이터가 최소 n개 이상이어야 유지.
이 함수는 결측값 처리 시 유용하다.



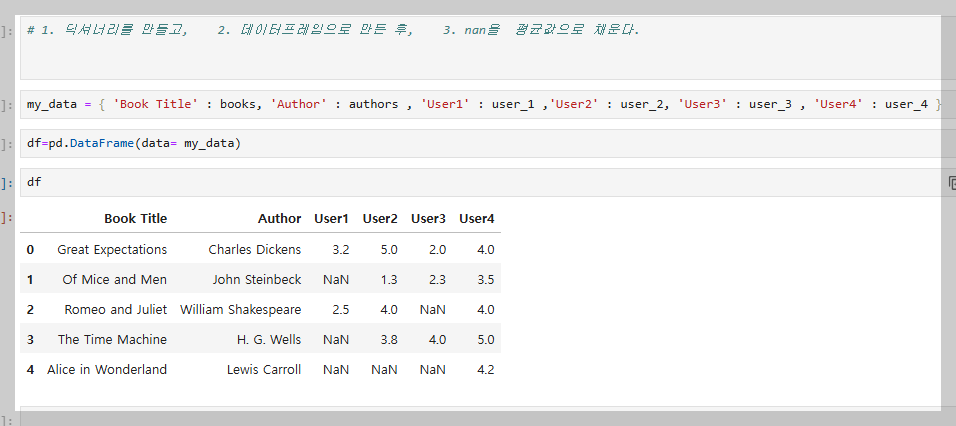
nan을 바꾸려면.fillna()를 쓰면 전체가 바뀌고 특정부분을 바꾸고 싶으면 [ ]리스트 를 이용하여 가져와서 특정부분을 바꿔줘하면된다.



지가 알아서 다 알아서 함 값이 없으면 셔츠 컬럼의 평균값을 넣고 싶어 값이 없으면 최소값으로 넣고 싶어 이런식으로 이런걸로 데이타를 채울 수 있다 그럴때 위 함수들을 사용하면된다 이젠느 컬럼별 평균으로 엔에이엔을 체운다하면 이렇게 사용이 가능하다




문자열 컬럼도 있어서 에러가 뜨는 것이다 그렇기떄문에 바꿔줘야한다
df.mean(numeric_only=True)를 써주고 하면된다

CSV 파일은 글로벌 표준으로 많이 사용되며, 판다스를 이용해 읽어서 처리할 수 있다.
JSON 파일 역시 판다스를 통해 읽고 처리할 수 있다.
이렇게 읽은 데이터는 데이터프레임으로 변환되어 분석에 사용된다.
데이터가 많을 경우, 예를 들어 3313개처럼 많은 데이터를 다룰 때는, 기본적으로 **처음 5개(head())와 끝 5개(tail())**를 보여준다.
또한, 필요한 데이터를 가져올 수 있는 전용 사이트나 API도 존재해 데이터를 손쉽게 확보할 수 있다.
csv파일을 읽어서 처리한다 => 글로벌 표준
JSON 파일도 읽어서 처리한다
읽어서 => 데이터 프레임으로 만들어서 분석한다!
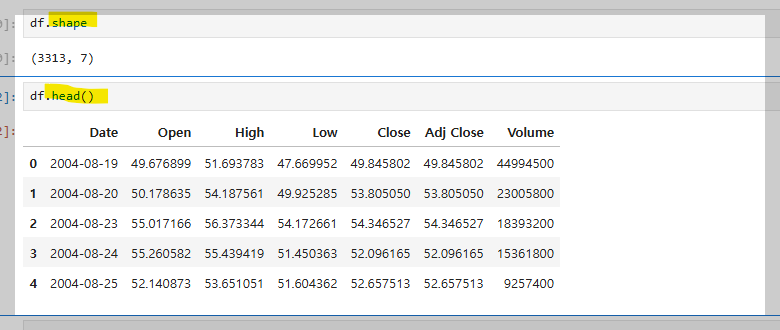

shape는 데이터프레임의 기본적인 정보를 제공하며, 데이터의 행과 열의 크기를 알려준다.
head()는 데이터프레임의 처음 5개 데이터를 보여준다.
그렇다면 끝에서 5개를 보고 싶다면? **tail()**을 사용한다.
또한, head()와 tail() 모두 파라미터로 보고 싶은 개수를 지정할 수 있다.
파라미터에 숫자를 입력하면 원하는 개수만큼 데이터를 출력할 수 있다.

(숫자로된)기초 통계 데이터를 확인하려면 df.describe() 함수를 사용한다.
결과 값 중 3.313000e+03과 같은 형식은 지수 표기법으로, +03은 10의 3승을 곱하라는 의미이다.
즉, 해당 값은 **3.313000 * 10 ** 3**으로 계산된다.
이 표기법은 큰 숫자나 작은 숫자를 간결하게 표시하기 위해 사용된다.

데이터 타입은 매우 중요하다. 예를 들어, 우리는 데이터를 년-월-일 형식으로 보지만, 판다스는 이를 기본적으로 문자열로 인식한다.
이 때문에 데이터 타입이 **문자열(object)**로 표시되는 것이다.
문자열 데이터는 날짜로서의 연산이 불가능하므로, 파이썬이 이해할 수 있는 날짜 형식으로 변환하는 코드가 필요하다.
이를 날짜/시간 데이터로 변환하면 요일 정보를 가져오거나, 특정 날짜의 주식 정보처럼 날짜와 관련된 다양한 분석을 할 수 있게 된다.
또한, 데이터 타입을 명확히 설정하면 데이터의 메모리 사용량도 확인할 수 있어, 효율적인 데이터 처리가 가능하다.

중복된 값이 많은 컬럼을 카테고리컬 데이터라고 한다.
대표적으로 성별처럼 값의 종류가 제한적인 데이터가 이에 해당한다.
예를 들어, 데이터가 4천만 개의 행을 가지고 있어도, 성별 컬럼은 '남'과 '여' 두 가지 값만 존재할 수 있다.
또한, 주소 데이터에서 101동 2014호처럼 상세 정보는 다르지만, 구나 시 정보는 동일할 수 있다.
이처럼 동일한 값이 반복되는 데이터를 카테고리컬 데이터라고 하며, 이를 처리하거나 분석할 때 유용한 함수들을 알아보겠다.
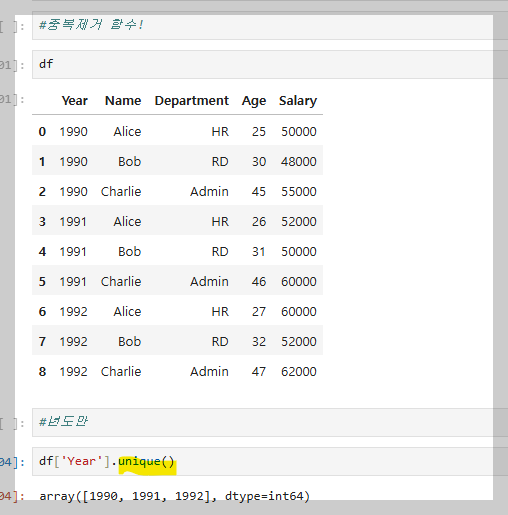

- 중복 제거 함수: .unique()
특정 컬럼에서 고유한 값들만 추출한다.
- 유니크한 값의 개수 확인 함수: .nunique()
특정 컬럼에서 고유한 값의 개수를 반환한다.
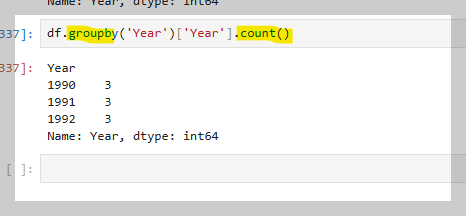
Year 컬럼의 고유한 값을 확인하거나 그 개수를 알고 싶을 때 사용할 수 있다.


groupby('묶어줄컬럼'): 특정 컬럼을 기준으로 데이터를 그룹화한다.
그룹화된 데이터를 활용하려면 집계 함수나
연산(예: sum(), mean(), count())을 사용해야 실제로 그룹화된 결과를 확인할 수 있다.


- 판다스는 내부적으로 NumPy를 사용하므로, NumPy의 기능을 활용하여 데이터를 처리한다.
- 코드에서 빨간 경고 메시지가 뜨는 이유는 최신 버전이 아닌 방식을 사용했기 때문이다. 실행은 되지만, 더 적합한 방식으로 대체하라는 워닝 메시지를 나타낸 것이다.
최신 방식은?
sum, mean 등 함수를 문자열로 처리하면된다
그렇게 되면 agg() 함수와 리스트를 통해 두가지 값을 한번에 볼수 있다


아이디, 이메일, 젠더 컬럼이 있는 데이터프레임에서, 예를 들어 성별이 4천만 개의 데이터로 구성되어 있지만 젠더 컬럼에는 '남', '여' 두 가지 값만 존재한다고 가정한다.
이때 **각 성별의 개수를 세기 위해 사용하는 함수가 .value_counts()**이다.
- .value_counts()는 빨간 상자 부분이 값(벨류)에 해당하며, 해당 값의 개수를 세어준다.
또한, **groupby()**를 활용해서도 같은 작업을 수행할 수 있다.
- groupby('젠더')와 집계 함수(예: .count() 또는 .size())를 조합하여 성별 데이터의 개수를 구할 수 있다.
아래는 캐나다 집값 알려주는 사이트인데
https://www.livingin-canada.com/house-prices-canada.html
Canadian House Prices – Living in Canada
Toronto : Ottawa : Ontario : Vancouver : Calgary : Edmonton : Ottawa : Montreal : Halifax : Nova Scotia Average House Prices In Canada Traditionally, one of the major attractions of a move to Canada for many people has been the cost of housing compared wit
www.livingin-canada.com


이 사이프의 표를 가져오고 싶다
여기는 표가 2개있다 이걸 데이타 프레임으로 가져와보겠다




여러개가있을 수 있으니깐 리스트로 가져오는 것이다

근데 마지막줄을 광고라 없애겠다 그리
데이터를 바로 저장하고 싶다면 **inplace=True**를 사용하면 된다.
- inplace=True를 설정하면, 수정된 내용이 원본 데이터프레임에 즉시 반영되어 저장된다.
- 별도의 변수를 생성하지 않아도 원본 데이터가 업데이트된다.

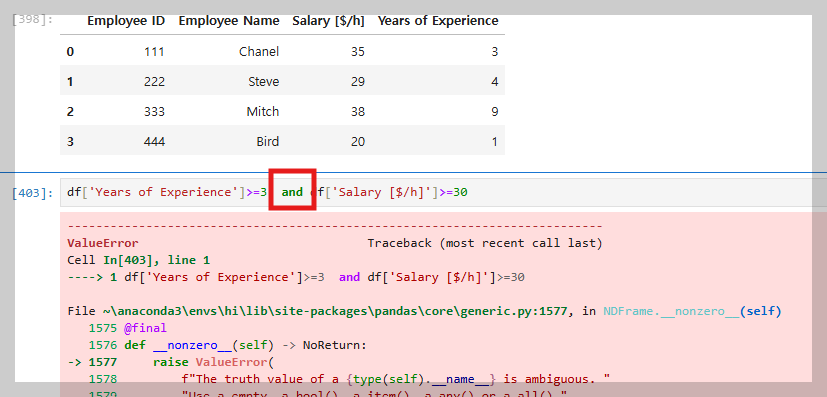

조건문일때 and 이다 지금은 가져와이기에 and 가 아니다 () & () 써주면된다


이거나는 or 이 아니라 | 를 쓰면된다
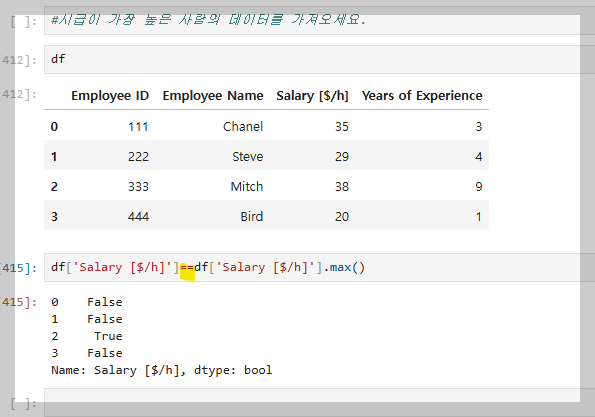

시급 컬럼이 같은지 여부를 확인하는 작업이다.
이제 True인 값만 가져오라는 의미로 필터링을 수행한다.
'Python > 이론정리' 카테고리의 다른 글
| 인코딩 vs 스케일링: 데이터 변환의 핵심 이해하기 (0) | 2025.01.30 |
|---|---|
| 회귀 모델 4종 비교: Linear, Logistic, Random Forest, XGBoost (0) | 2025.01.30 |
| 데이터 분석의 핵심: Pandas 주요 함수 정리 (0) | 2025.01.25 |
| 예측모델 및 분석대회 플랫폼 kaggle (1) | 2025.01.23 |
| 인공지능 시대의 추천 서비스: 데이터가 이끄는 혁신 (2) | 2025.01.16 |