문자열 가공은 판다스에서 .str 속성을 사용하여 간단히 처리할 수 있다. 데이터를 하나씩 가져오는 작업이 번거로울 수 있어, 판다스는 문자열 처리에 특화된 여러 가지 함수를 라이브러리처럼 제공한다. 아래는 문자열 가공과 관련된 함수들을 확인할 수 있는 사이트이다.
https://pandas.pydata.org/docs/reference/api/pandas.Series.str.upper.html
pandas.Series.str.upper — pandas 2.2.3 documentation
Converts first character of each word to uppercase and remaining to lowercase.
pandas.pydata.org

빨간 상자는 같은거고 뒤에 적어주면 각 이름의 갯수를 구할 수 있다.
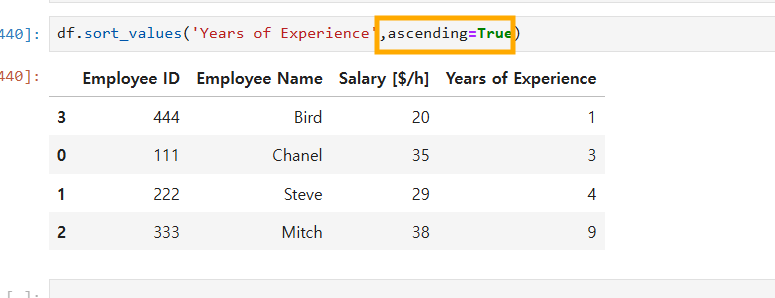
ascending=True 이 디폴드 값으로 되어 있다 만약 des 로하고 싶다하면 True를 False로 바꾸면된다.
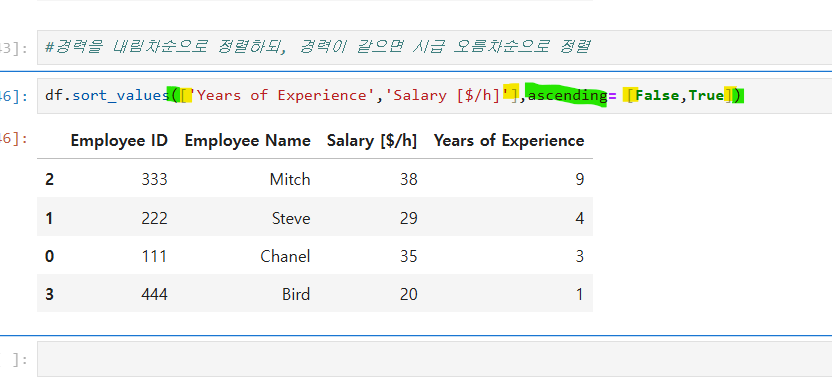
df.sort_values(['Years of Experience','Salary [$/h]'],ascending= [False,True])
sort_values()는 여러 열에 대해 순차적으로 정렬을 수행한다.
ascending=[False, True]를 사용하면 첫 번째 열은 내림차순으로, 두 번째 열은 오름차순으로 정렬한다.
정렬 기준을 열 단위로 다르게 설정할 수 있어 유연하게 정렬을 수행할 수 있다.
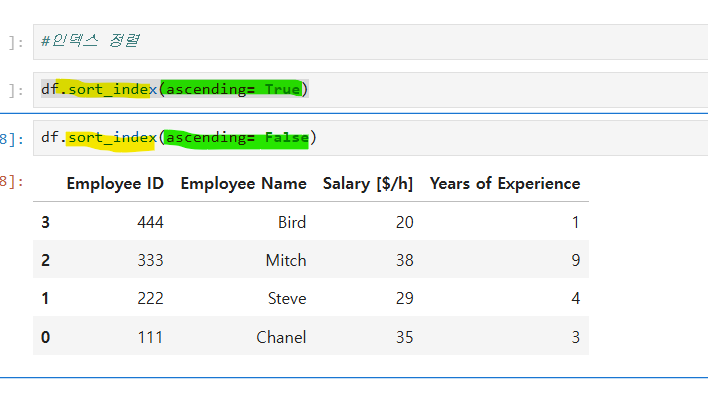
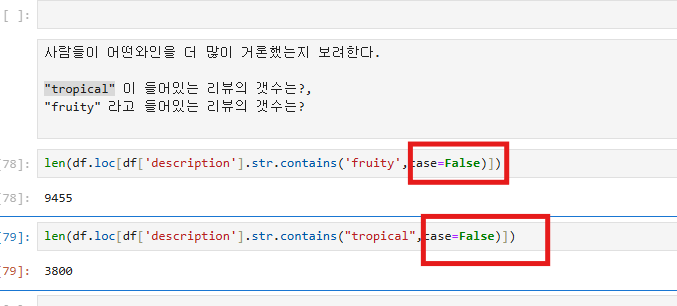
대소문자 구분안하고 하니깐 디폴트로 들어가는 case =True를 False 로 바꿔줘야한다!
'Python > 실습' 카테고리의 다른 글
| 파이썬 : 차트 (0) | 2025.01.24 |
|---|---|
| 파이썬 : 판다스 데이터 연결 (0) | 2025.01.23 |
| 파이썬: 랜덤 활용 및 날짜와 시간 다루기 (0) | 2025.01.21 |
| 파이썬: 함수 정의와 람다 표현식 (1) | 2025.01.21 |
| 파이썬: for, while 반복문과 range 함수의 활용 (2) | 2025.01.20 |