플롯
플롯 차트는 데이터를 점, 선, 막대 등의 형태로 시각화하여 추세, 분포, 비교, 구성 비율 등을
직관적으로 이해할 수 있도록 표현한다.


import matplotlib.pyplot as plt
plt.plot(x, y)
plt.show()


import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb


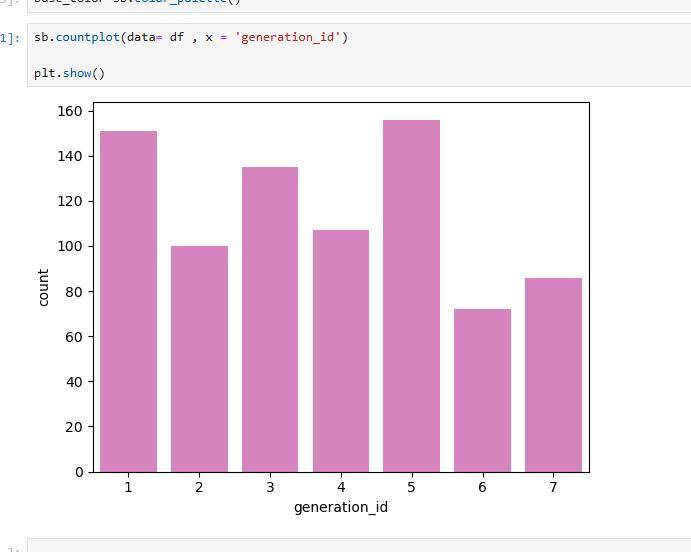
먼저 데이터 분석을 위해 세대(generation)가 몇 개인지 확인하고 데이터를 준비해야 한다.
이를 위해 pandas를 사용하여 데이터를 불러오고,
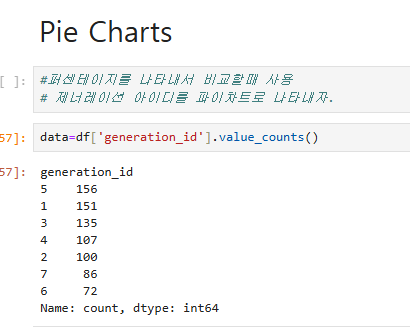
세대별로 고유값과 각 세대의 개수를 확인한다.
df['generation_id'].unique()를 사용하면 고유 세대 값을 확인할 수 있으며, df['generation_id'].value_counts()를 사용하면 각 세대별 개수를 집계할 수 있다.
이 과정에서 데이터를 시각화하기 위해 seaborn의 countplot()을 활용하는 것이 편리하다.
countplot() 함수는 지정된 컬럼값을 기반으로 각 항목의 개수를 자동으로 계산하고 막대 그래프로 표현해준다.
따라서 x='generation_id'만 설정하면 세대별 포켓몬 수를 쉽게 시각화할 수 있다. 이를 통해 세대별 분포를 한눈에 파악할 수 있다.

데이터 시각화에서 색상을 커스터마이징하기 위해 seaborn의 color_palette()를 활용할 수 있다. 이 함수는 기본 색상 팔레트를 생성하며, 리스트 형태로 반환되기 때문에 특정 색상을 선택할 수도 있다. 예를 들어, sb.color_palette()[3]을 사용하면 팔레트의 네 번째 색상인 빨간색을 선택할 수 있다.
이를 통해 원하는 색상을 지정하여 그래프의 가독성을 높이고, 시각적 효과를 개선할 수 있다.


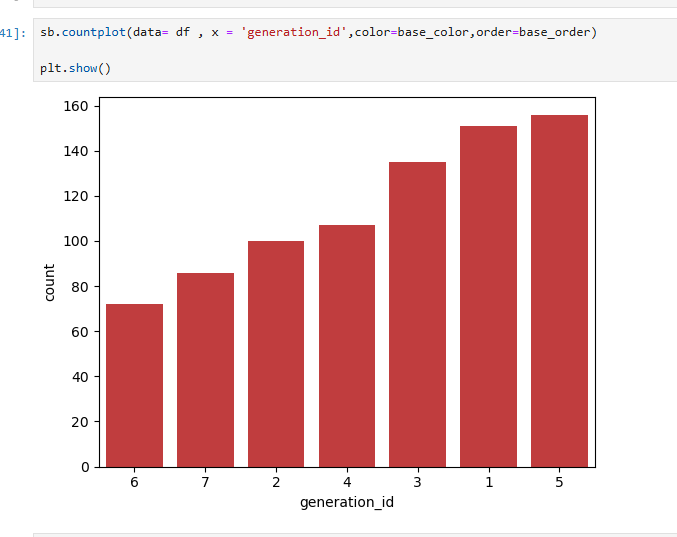
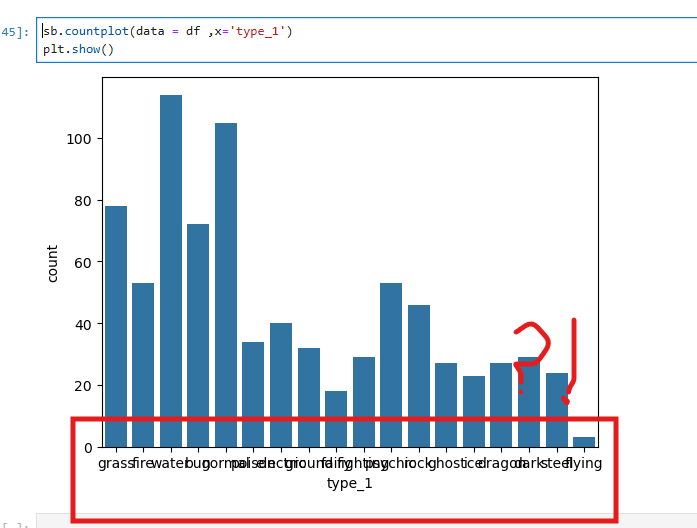
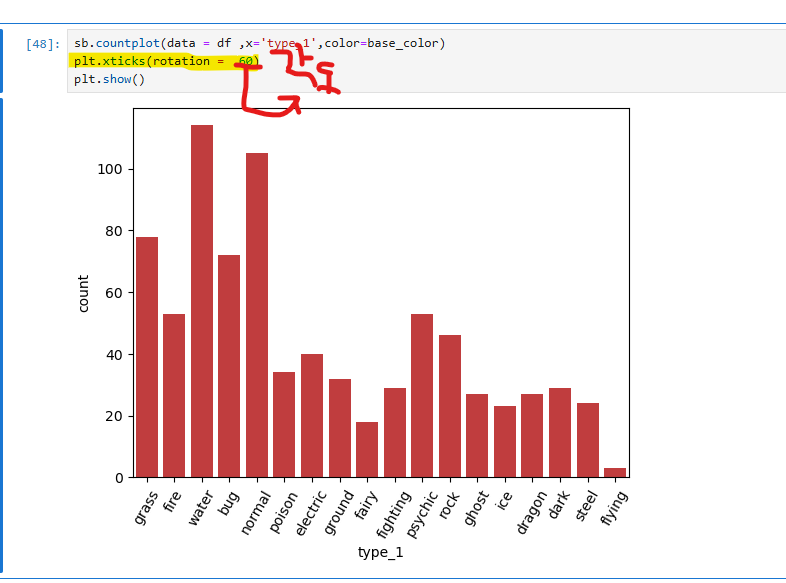
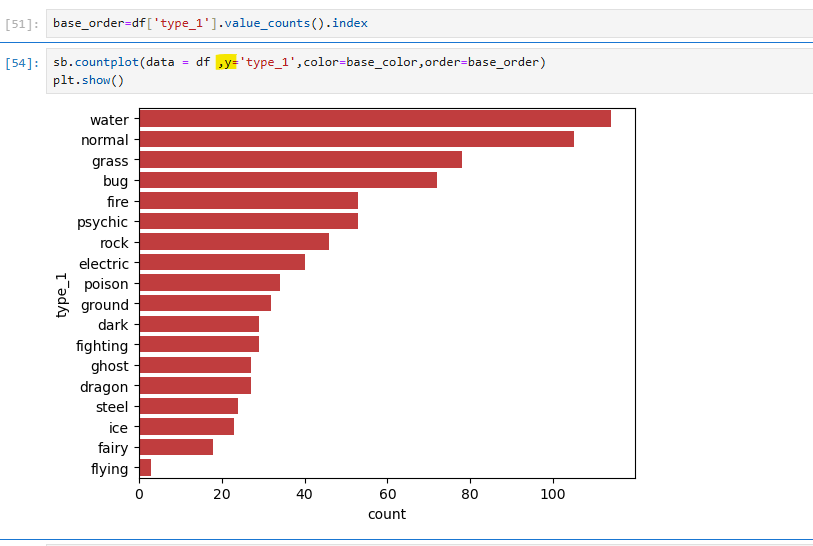
데이터 시각화에서 축의 가독성을 높이기 위해 rotation 옵션을 사용하여 x축 라벨의 각도를 설정하거나, order를 활용해 y축 항목의 순서를 정렬하는 방법이 있다.
sb.countplot(data=df, x='type_1')으로 포켓몬의 타입별 개수를 시각화할 때, x축 라벨이 겹치는 경우 plt.xticks(rotation=45)를 통해 각도를 조정하여 가독성을 개선할 수 있다.
또한, y축 항목을 특정 순서로 정렬하려면 value_counts()를 활용하여 데이터를 정렬한 뒤, order 매개변수에 설정된 순서를 전달하면 된다. 이 방법은 데이터의 시각적 표현을 보다 명확하고 직관적으로 만들 수 있다.
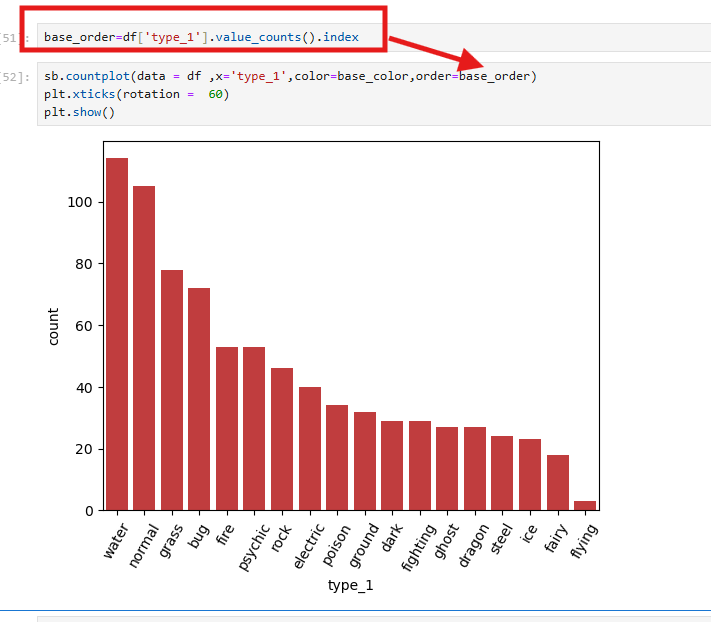
데이터 시각화에서 막대그래프의 항목 순서를 정렬하기 위해 value_counts()를 사용하여 데이터를 빈도순으로 정렬한 후, order 매개변수에 전달할 수 있다.
base_order = df['type_1'].value_counts().index를 사용하여 type_1 열의 값을 빈도순으로 정렬한 인덱스를 생성하고, 이를 countplot의 order 옵션에 전달하여 그래프 항목을 정렬할 수 있다.
파이차트
파이썬의 파이차트는 데이터를 시각적으로 표현할 때,
각 항목의 비율을 퍼센테이지로 나타내어 비교하는 데 사용한다.
주로 항목 간의 상대적인 크기를 강조하거나,
전체에서 특정 항목이 차지하는 비중을 시각적으로 이해하기 쉽게 표현하는 데 유용하다.
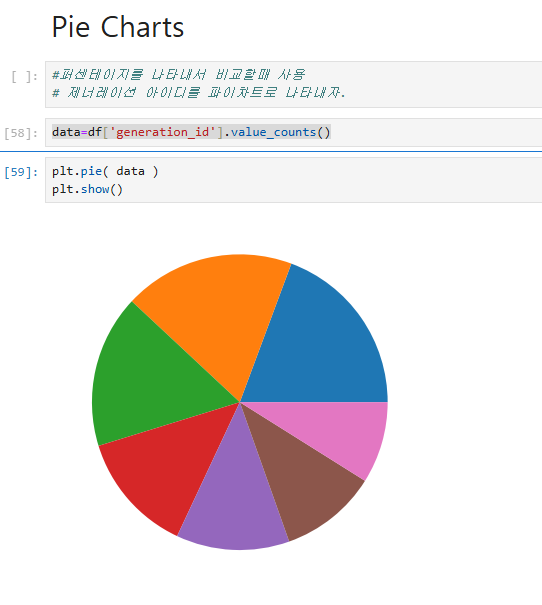
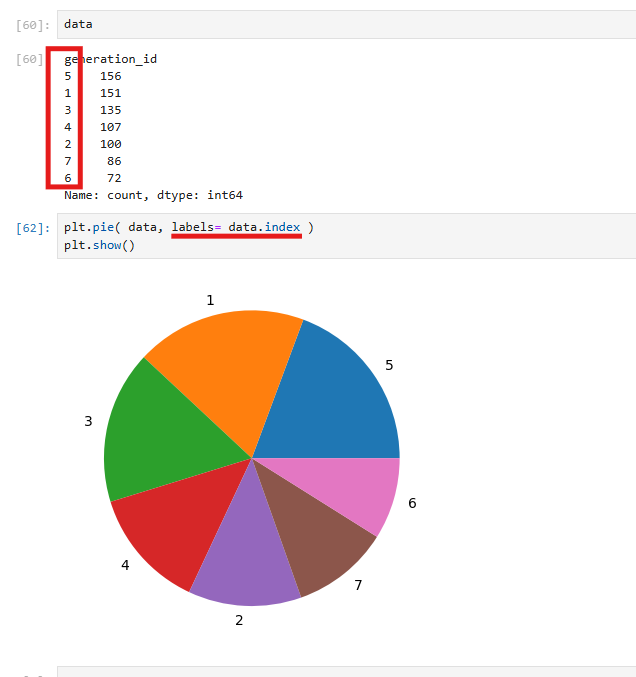
데이터프레임 data를 사용하여 Matplotlib의 plt.pie를 통해 파이차트를 보여준다.
data는 특정 항목의 값과 개수를 나타내는 시리즈 형태로, generation_id 항목의 비율이 파이차트로 시각화되었다. labels=data.index를 통해 각 항목에 라벨을 지정했으며, plt.show()를 사용해 차트를 출력했다. 결과적으로 각 항목의 비율이 원형 차트로 표현되어 데이터 간의 상대적인 크기를 비교할 수 있다.
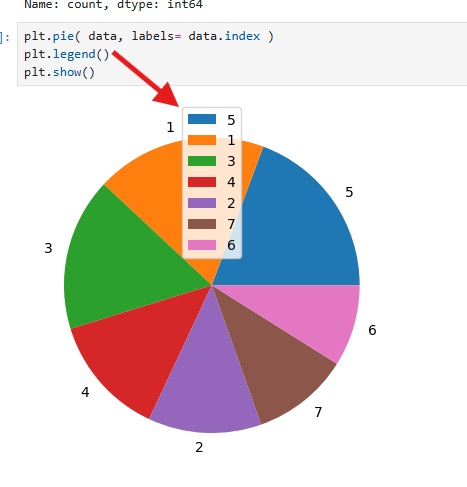
, labels로 항목 이름을 지정했으며,
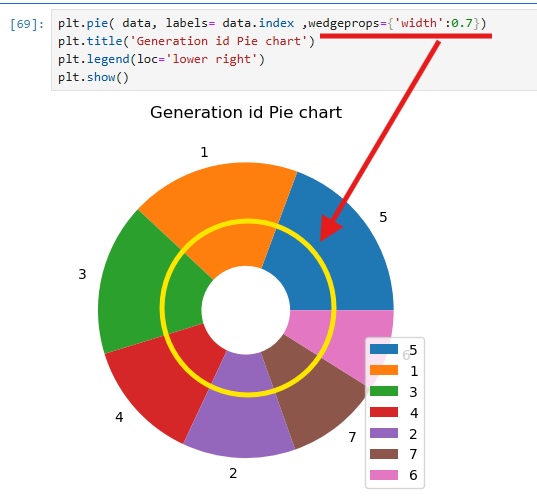
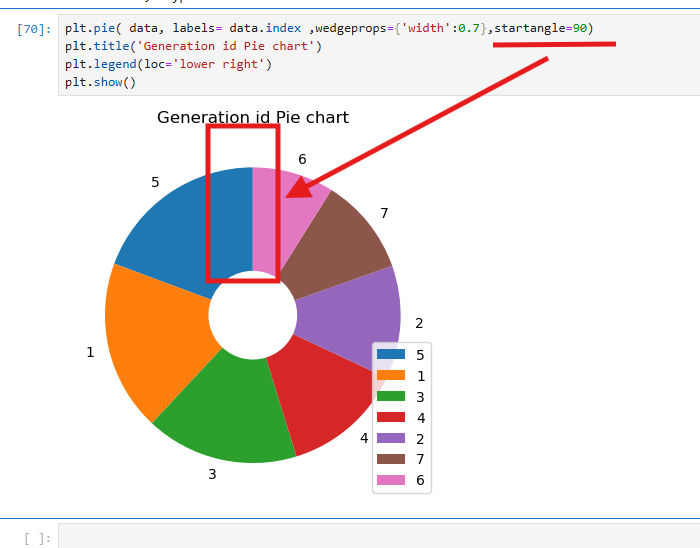
데이터의 비율을 표현하기 위해 plt.pie를 사용하였고
wedgeprops로 두께를 설정하고,
startangle로 시작 각도를 90도로 지정했다.
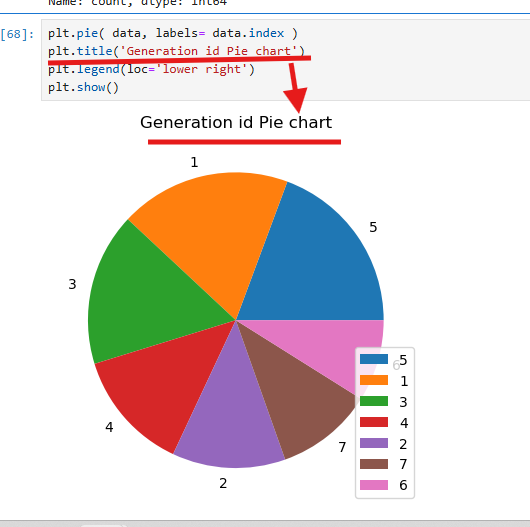
제목은 plt.title로 설정되었으며,
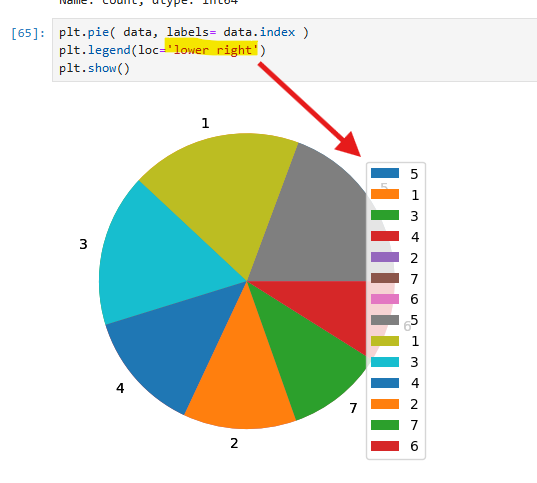
범례는 plt.legend로 하단 오른쪽에 추가되었다.
출력된 차트는 각 항목의 비율을 시각적으로 비교할 수 있도록 원형으로 표현되었다.
히스토그램
히스토그램은 데이터를 구간(bin)으로 나누어
각 구간에 속하는 데이터의 빈도를 막대그래프로 표현하는 시각화 도구로,
데이터의 분포와 패턴을 이해하는 데 사용된다.
히스토그램은 데이터를 특정 범위(구간)로 나누어 각 구간에 해당하는
데이터의 개수를 세어 막대그래프로 표시하는 차트이다.
여기서 구간은 bin이라 하며, 여러 구간을 사용할 경우 bins로 설정하여 시각적으로 데이터를 분포에 따라 표현한다.
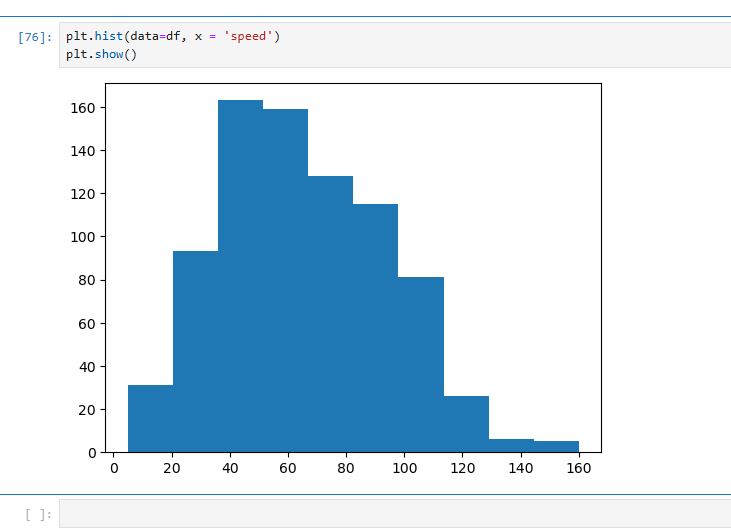
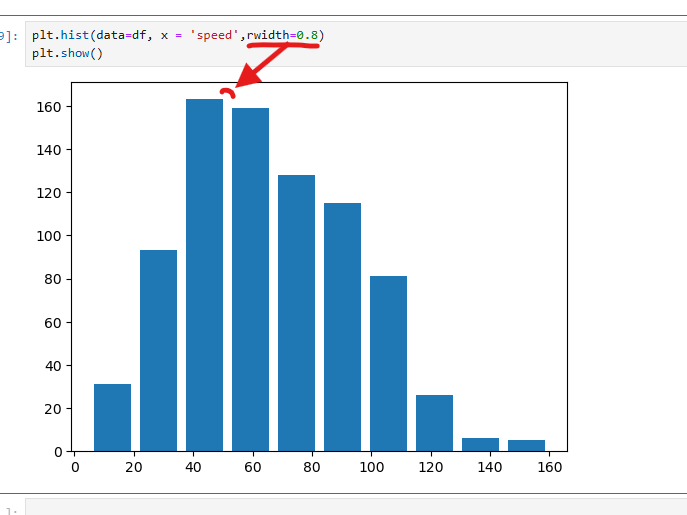
히스토그램은 기본적으로 구간(bin)을 10개로 나누어 데이터를 시각화하며,
이로 인해 막대가 서로 붙어 보이는 단점이 있다.
이러한 문제를 해결하기 위해 rwidth 매개변수를 사용하여 막대의 너비를 조정할 수 있다.
rwidth=0.8로 설정하면 막대 간의 간격이 생기면서 시각적으로 더 구분하기 쉬운 히스토그램을 만들 수 있다. rwidth 값은 0과 1 사이의 실수로, 원하는 너비를 지정할 수 있다. 이를 통해 히스토그램의 가독성을 개선할 수 있다.
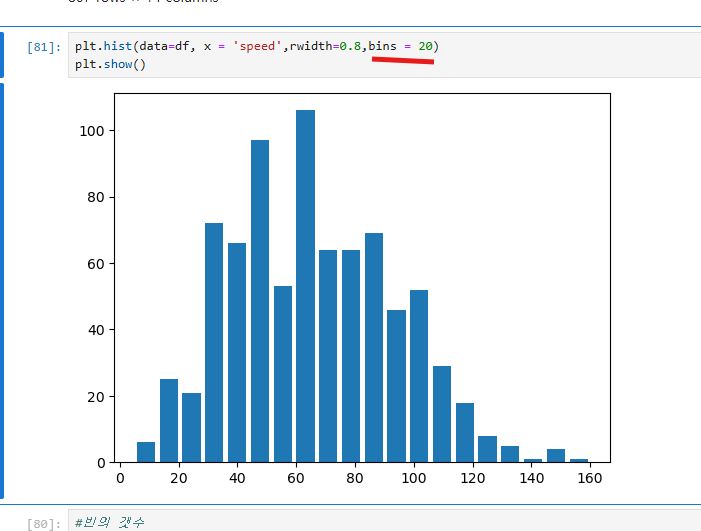
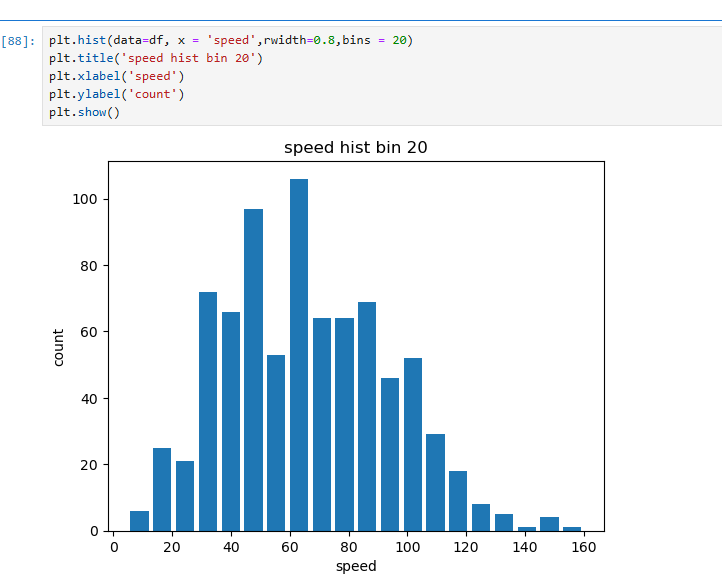
이 코드는 히스토그램을 생성하며, bins=20을 설정하여 데이터를 20개의 세밀한 구간으로 나누고,
plt.title()로 그래프 제목을 설정하고, plt.xlabel()과 plt.ylabel()로 각각 x축과 y축의 라벨을 추가하여 그래프의 가독성을 높였다.
이를 통해 데이터를 더 세밀한 구간으로 나누어 분포를 자세히 분석할 수 있도록 하였다.
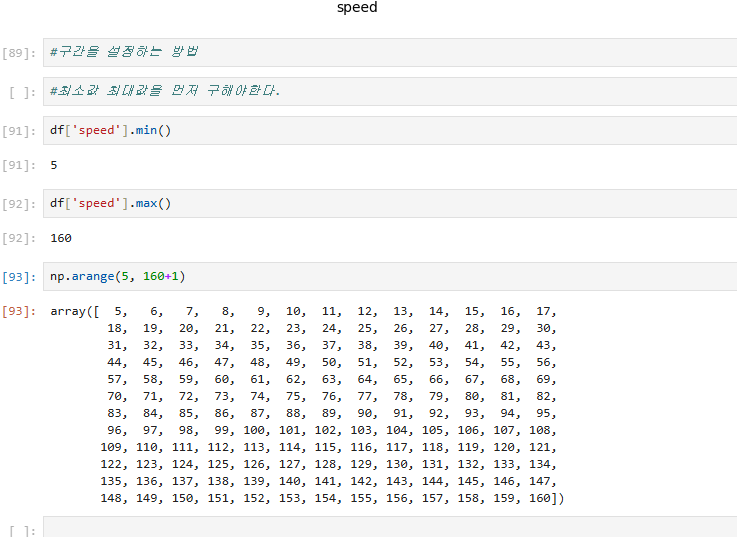
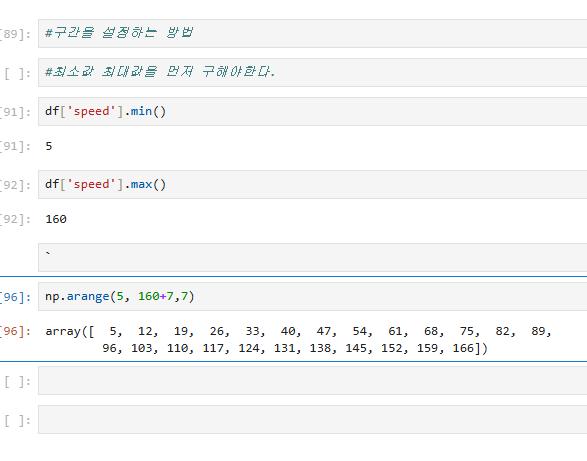
데이터를 분석하기 위해 최소값과 최대값을 구해야 한다.
df['speed'].min()과 df['speed'].max()를 사용하여 최소값(5)과 최대값(160)을 구하고, np.arange()를 활용하여 특정 간격으로 구간을 생성한다
이를 통해 my_bin이라는 구간 배열을 정의하며, 이 배열을 plt.hist()의 bins 매개변수에 전달하여 히스토그램을 생성한다.
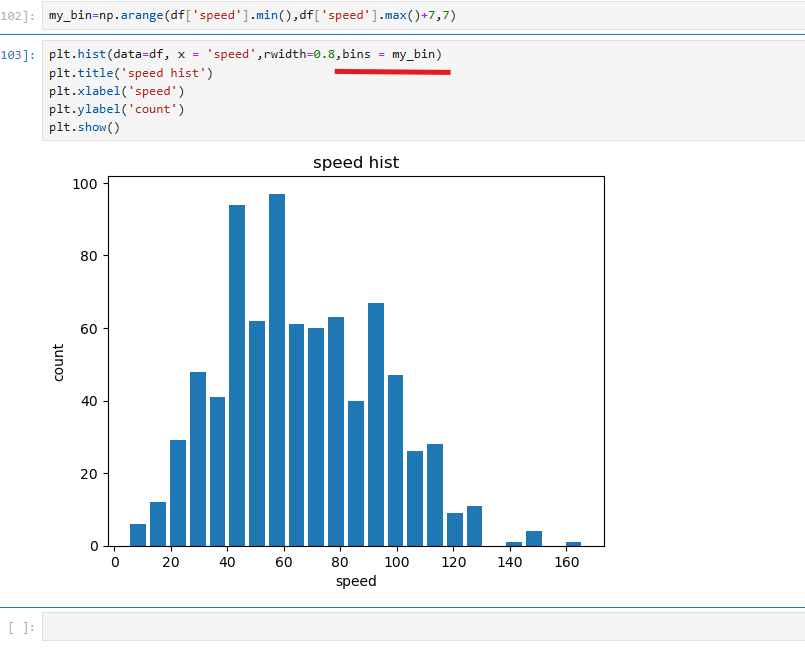
rwidth=0.8를 통해 막대 너비를 조정하고, plt.title(), plt.xlabel(), plt.ylabel()로 각각 제목과 축 라벨을 설정하여 그래프의 가독성을 높였다. 이러한 과정을 통해 데이터를 세밀하게 나누고, 원하는 구간별 데이터 분포를 시각적으로 확인할 수 있다.
Subplots
`Subplots`는 하나의 창에 여러 그래프를 배치하여 데이터를 동시에 비교하고
시각화할 수 있는 Matplotlib 기능이다. `plt.subplot()`과 `plt.subplots()`를 사용해
그래프를 구성하며, 다양한 데이터를 효율적으로 표현할 수 있다.
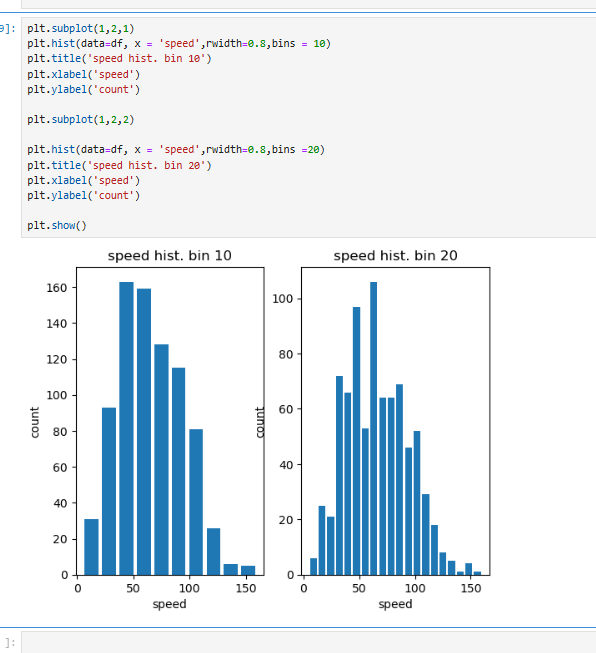
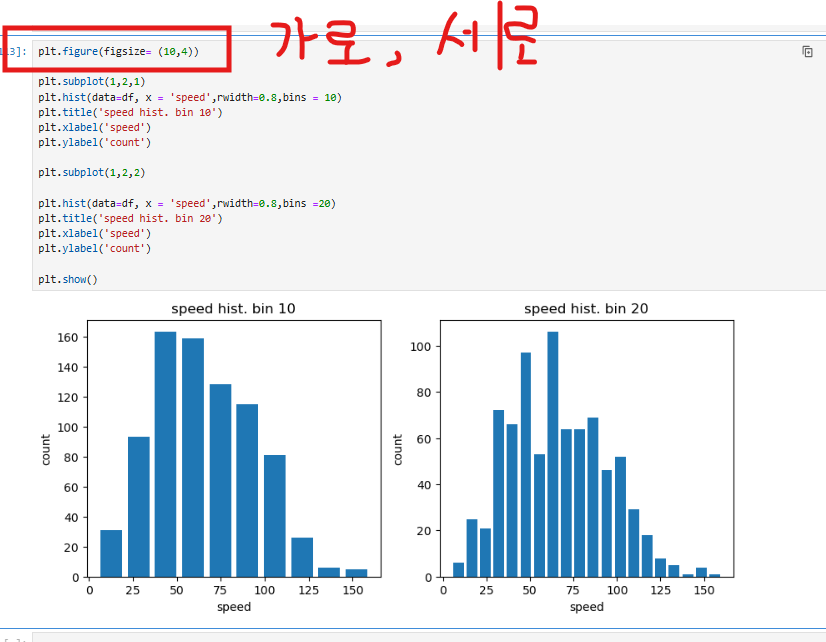
Matplotlib의 subplot을 사용하여 하나의 그래프 창에 여러 개의 플롯을 배치하는 방법을 보여준다. plt.subplot(1, 2, 1)은 1행 2열로 나누어진 플롯의 첫 번째 위치에 그래프를 그리고, plt.subplot(1, 2, 2)는 두 번째 위치에 그래프를 배치한다.
또한, plt.figure(figsize=(10, 4))로 전체 그래프 창의 크기를 설정하여 시각적 가독성을 높인다. 예제에서는 두 개의 히스토그램을 각각 다른 구간(bins) 값으로 표현하여 비교하였으며, 첫 번째는 구간을 10으로 설정하고,
두 번째는 구간을 20으로 설정하였다. 이를 통해 데이터를 다양한 구간 크기로 나누어 분포를 비교하고 분석할 수 있다.
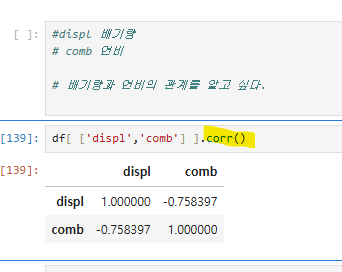
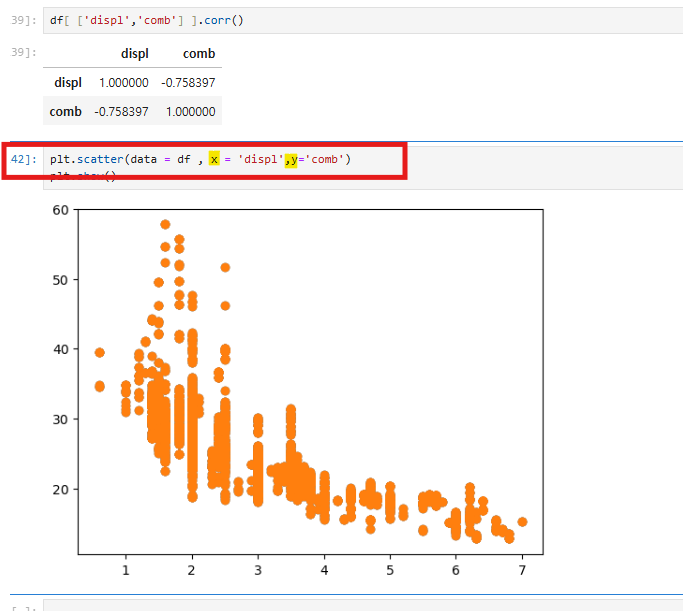
피어슨 상관관계는 두 변수 간의 상관 정도를 -1에서 1 사이의 값으로 나타내며, -1은 완전한 반비례, 1은 완전한 정비례, 0은 상관관계가 없음을 의미한다. 대각선 값은 자기 자신과의 관계이므로 의미가 없으며, 실제 상관관계는 대각선 외의 값에서 확인한다.
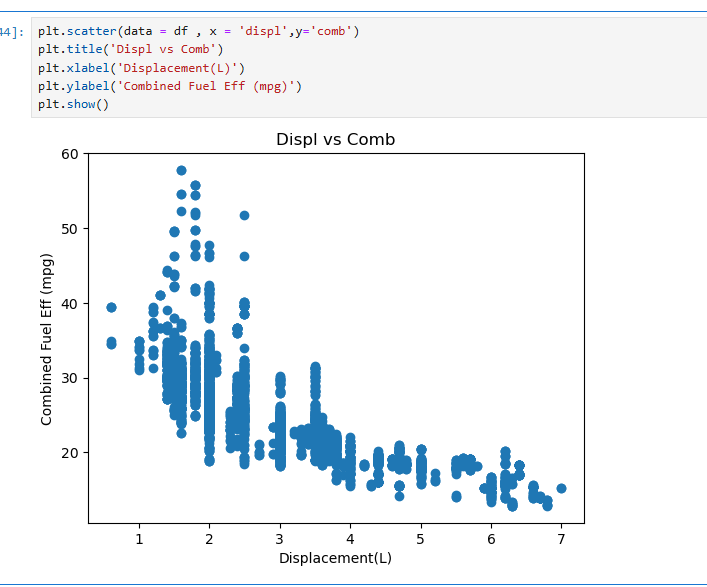
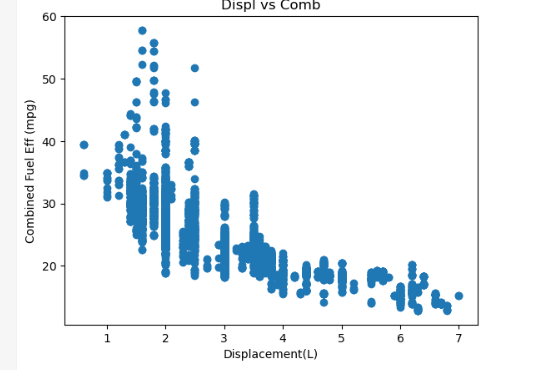
두 변수의 관계를 시각적으로 표현하려면 plt.scatter(data=df, x='displ', y='comb')를 사용한다. 배기량(displ)과 연비(comb)는 반비례 관계를 가지며, 배기량이 증가할수록 연비는 낮아지는 패턴을 관찰할 수 있다. 이를 통해 변수 간의 상관관계를 쉽게 분석할 수 있다.
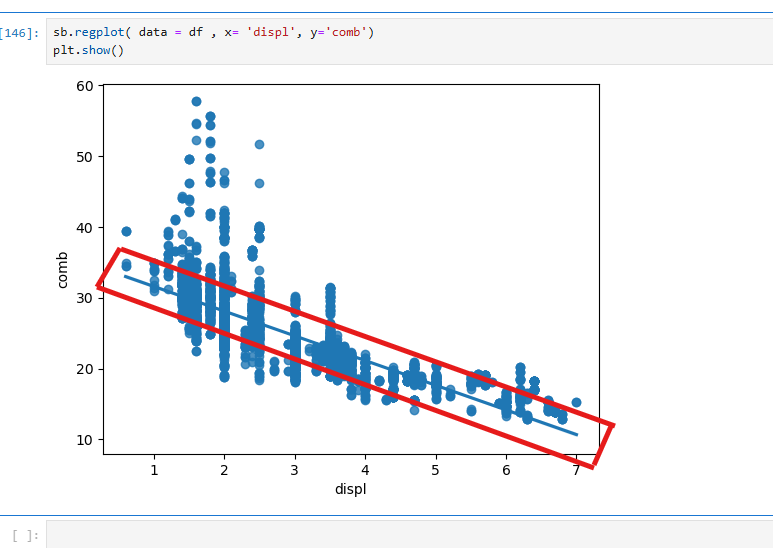
reg는 회귀를 의미하며, 리그레이션(Regression)은 데이터를 기반으로 가장 적합한 선(모델)을 찾는 과정을 말한다.
리그레이션은 데이터를 학습(fit)하여 변수 간의 관계를 나타내는 선형 또는 비선형 모델을 생성하는 것을 의미한다.
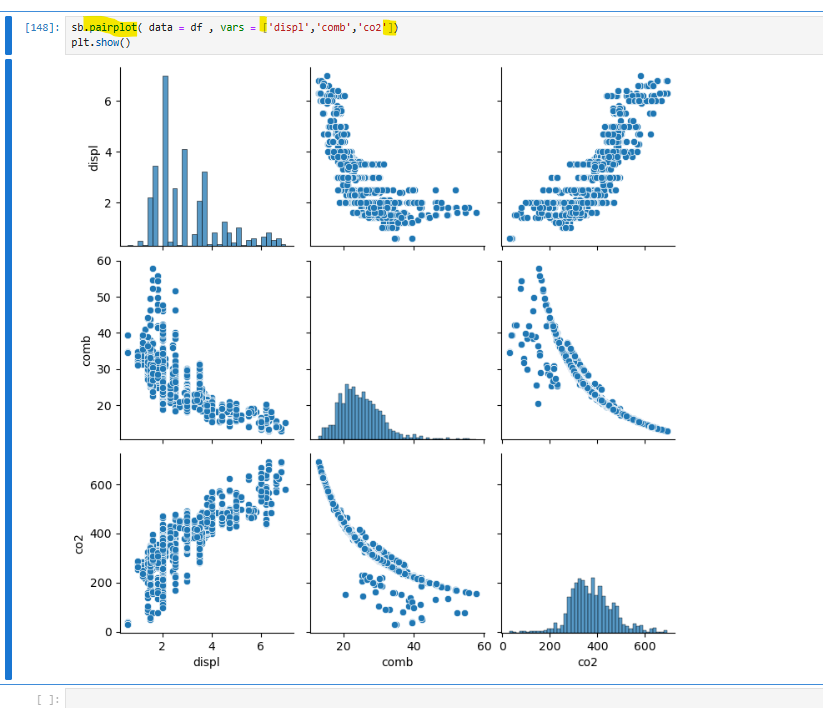
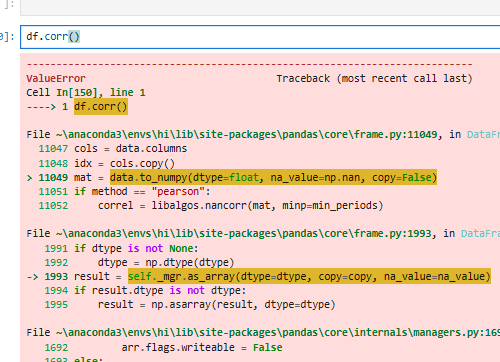
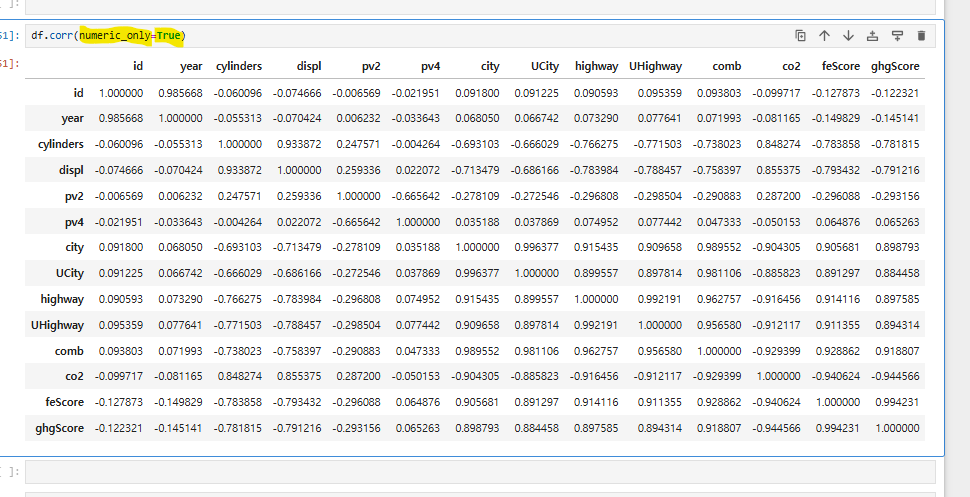
왼쪽은 df.corr() 메서드를 사용하여 데이터프레임의 상관관계를 계산하는 과정에서 발생한 오류를 보여준다. 오류의 원인은 데이터프레임에 숫자가 아닌 문자열 데이터가 포함되어 있기 때문이다. 이를 해결하기 위해 numeric_only=True 옵션을 추가하여 숫자 데이터만 상관관계 계산에 포함하도록 지정한다.
수정된 코드인 df.corr(numeric_only=True)를 사용하면 데이터프레임에서 숫자형 열만 필터링하여 상관관계를 계산할 수 있으며, 결과는 변수 간의 상관도를 나타내는 행렬로 출력된다. 이를 통해 비숫자 데이터로 인한 오류를 방지하고 올바른 상관관계 분석을 수행할 수 있다.
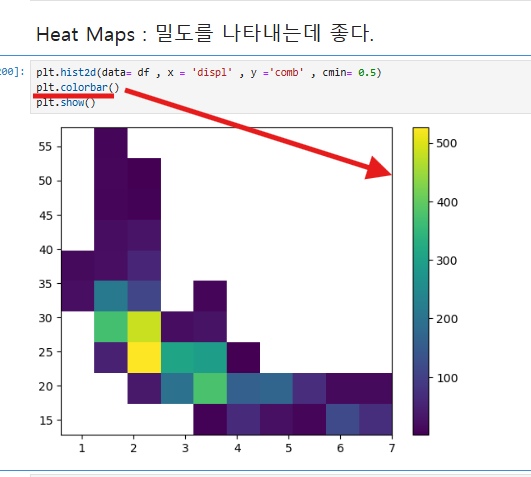
스캐터 플롯은 데이터가 한곳에 뭉쳐 있을 경우 가독성이 떨어질 수 있다. 이를 보완하기 위해 히트맵(Heatmap)을 사용하면 데이터의 밀도를 시각적으로 표현할 수 있어 한눈에 파악하기 좋다. 히트맵은 특히 데이터가 많이 겹치는 경우 밀도를 효과적으로 나타내는 데 유용하다.
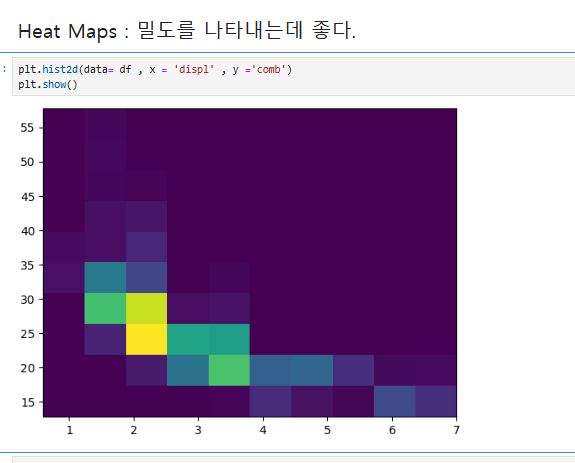
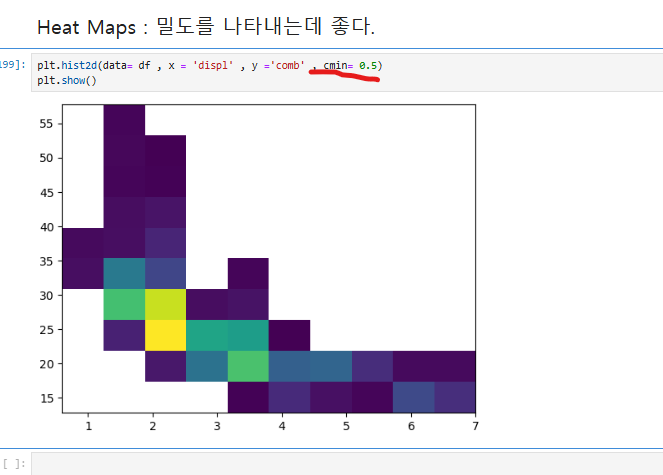
plt.hist2d()를 사용하여 x축(displ)과 y축(comb) 데이터를 기반으로 2차원 히스토그램을 생성했으며, cmin=0.5를 설정 하였다.
cmin=0.5는 바탕을 하얗게 해준는거라 생각하면된다
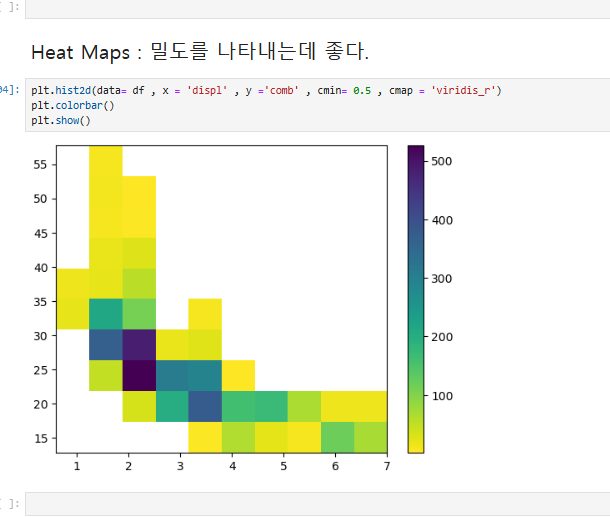
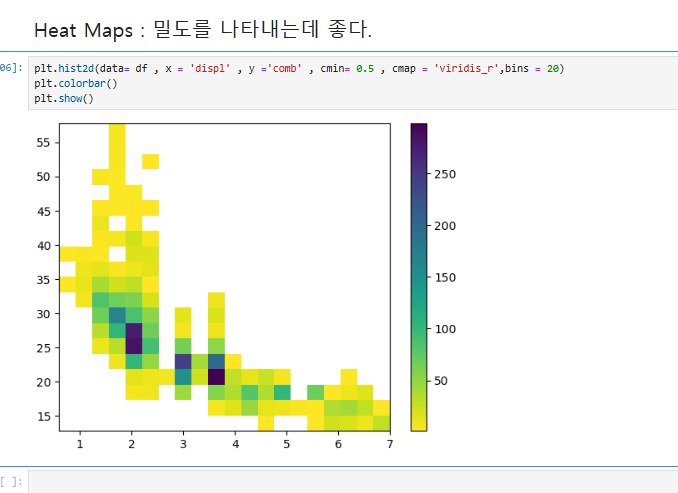
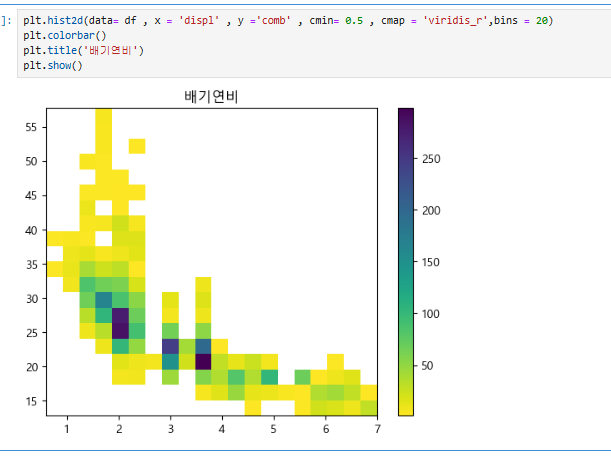
cmap='viridis_r'는 색상 맵을 설정하는 옵션으로, viridis_r는 Viridis 색상 맵을 반대로 적용한다
plt.colorbar()를 사용하여 히트맵의 색상과 데이터 밀도의 관계를 보여주는 색상 막대를 추가했다.
## 한글 처리를 위해서는, 아래 코드를 실행하시면 됩니다.##
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')'Python > 실습' 카테고리의 다른 글
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |
|---|---|
| 파이썬 : 머신러닝, 데이터 프리프로세싱 (3) | 2025.01.24 |
| 파이썬 : 판다스 데이터 연결 (0) | 2025.01.23 |
| 파이썬: 판다스를 활용한 문자열 데이터 가공 (0) | 2025.01.22 |
| 파이썬: 랜덤 활용 및 날짜와 시간 다루기 (0) | 2025.01.21 |