머신러닝이란?

머신러닝으로 할 수 있는 일은 손으로 쓴 우편번호의 숫자를 자동으로 판별하고,
의료 영상 이미지 기반으로 질병을 중앙에서 판단하며, 의심되는 신용카드 거래를 감지하고,
블로그 글을 주제별로 분류하며, 고객들을 취향이 비슷한 그룹으로 묶는다.
문제와 데이터를 이해하기 위해,
가지고 있는 데이터가 원하는 문제의 답을 가지고 있는지 확인하고,
문제를 가장 잘 해결할 수 있는 머신러닝 방법이 무엇인지 선택하며,
문제를 해결하기에 충분한 데이터를 모았는지 검토하고,
머신러닝의 성과를 어떻게 측정할 것인지 계획한다.이 그림은 머신러닝을 이해하고 활용하기 위한 기본 개념과 알고리즘 분류를 설명하며, 지도학습과 비지도학습으로 나뉘는 두 가지 학습 방법에 대해 각 알고리즘의 주요 활용 사례를 정리한 구조도이다. 지도학습에서는 입력 데이터와 정답(label)을 사용하여 모델을 학습시키며,
분류 문제에서는 K-최근접 알고리즘(KNN), 서포트 벡터 머신(SVM), 결정 트리, 로지스틱 회귀 등의 알고리즘을 사용하여 주어진 데이터를 특정 범주로 분류할 수 있고, 예측 문제에서는 회귀 알고리즘으로 연속적인 값을 예측한다.
예를 들어, 집값이나 자동차 금액을 예측하는 것은 수치 예측 문제로 지도학습에 속하며, 빨간불·파란불 예측이나 횡단보도 여부를 판단하는 것은 정해진 범주로 데이터를 분류하는 지도학습 사례이다.
반면, 비지도학습에서는 정답(label)이 없는 데이터를 기반으로 패턴을 찾거나 데이터를 그룹화하며, 군집화 알고리즘에서는 K-평균, K-중앙값, DBSCAN 등의 평할 기반 군집화 방법과 병합적/분할적 방식의 계층적 군집화를 통해 데이터를 유사한 그룹으로 나누는 데 사용된다. 이러한 알고리즘은 데이터 분석, 분류, 추천 시스템, 이상 탐지 등 다양한 분야에 활용할 수 있다.
인공지능이란?
인공지능은 사람의 언어를 컴퓨터가 이해할 수 있도록 숫자(벡터)로 변환하며, 이 과정은 자연어 처리(NLP) 기술을 통해 이루어진다. 텍스트 데이터는 단어 임베딩(Word Embedding)이나 원-핫 인코딩 같은 방법으로 숫자 형태로 바뀌고, 변환된 숫자 데이터는 AI 모델이 학습하고 분석할 수 있도록 활용된다.
머시너링 전처리하기
머신러닝 전처리는 데이터의 품질을 개선하고, 결측치나 이상치를 처리하며,
모델이 학습하기 적합한 형태로 변환하여 성능과 정확도를 높이기 위해 수행한다.
학습을 위해서는 데이터를 숫자로 변환해야 한다. 내가 예측하고 싶은 데이터의 컬럼을 미리 작업해야 하며,
우선 데이터에 결측치(NaN)가 있으면 삭제하거나 적절히 처리한다.
예측하고자 하는 목표 변수는 y 변수로 설정하고, 나머지 특징 데이터를 X 변수로 설정한다. 예를 들어, 구매 여부를 예측하고 싶다면 구매 여부를 y 변수로 설정하고, 국가, 나이, 급여와 같은 나머지 정보를 X 변수로 설정한다.
#카테고리컬 데이타에서 종류가 3개 이상이면 원핫 인코딩을 해야하고
#종류가 2개이면 0과 1로 바꾸면된다.
컴퓨터가 학습할 수 있게 바꿔주는 코드 4줄
from sklearn.preprocessing import LabelEncoder , OneHotEncoder
from sklearn.compose import ColumnTransformer
#컬럼 트랜스포머를 만들때는 튜플의 세번쨰에 원하는 결컴인덱스를 넣는다.
ct=ColumnTransformer( [('encoder',OneHotEncoder(),[ 0 ])] , remainder='passthrough')
LabelEncoder: 범주형 데이터를 정수로 변환하는 간단한 인코딩 도구로, 예제에서 y 값을 0과 1로 변환하였다.
encoder = LabelEncoder()
y_encoded = encoder.fit_transform(y)
OneHotEncoder와 ColumnTransformer: 범주형 데이터가 여러 개일 경우, 이를 원-핫 인코딩으로 변환하며, 특정 열만 선택적으로 인코딩할 수 있다. ColumnTransformer를 사용하여 원-핫 인코딩을 적용할 열을 지정하고, 나머지 열은 그대로 유지한다.
ct = ColumnTransformer([('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X_transformed = ct.fit_transform(X)
이를 통해 범주형 데이터를 숫자로 변환하고, 머신러닝 모델이 학습할 수 있도록 준비할 수 있다. ColumnTransformer는 여러 열을 동시에 처리하거나, 특정 열만 변환할 때 유용하다.

Feature Scaling은 머신러닝에서 데이터를 표준화(Standardisation)하거나 정규화(Normalisation)하여 학습을 용이하게 만드는 과정이다. 표준화는 데이터를 평균 0, 표준편차 1로 변환해 범위를 균일하게 하고, 정규화는 데이터를 0과 1 사이로 변환하여 비교를 쉽게 한다. 이는 데이터 간 스케일 차이를 줄여 모델이 특정 변수에 치우치지 않고 정확하게 학습할 수 있도록 돕는다.
X와 y에 문자열 데이터가 포함되어 있다면 이를 숫자로 변환하는 작업이 필요하다. 문자열 데이터가 3개 이상 범주를 가지면 원-핫 인코딩을 사용하는 것이 좋고, 범주가 2개뿐이라면 레이블 인코딩으로 0과 1로 변환하는 것이 효율적이다.
국가 정보는 범주가 3개 이상이므로 원-핫 인코딩을 수행한다. 이를 위해 ColumnTransformer와 같은 라이브러리를 활용하며, 원-핫 인코딩이 필요한 컬럼(국가 정보)을 지정하고 나머지 컬럼은 그대로 유지하도록 설정한다. 이후 fit_transform을 통해 데이터를 변환하면 X의 처리 과정이 완료된다.
엑스는 이차원이어야한다 만약 일차원이라면 이차원으로 만들어 줘야한다 .to_frame()
y 변수(구매 여부)는 범주가 "예" 또는 "아니오"로 2개뿐이므로 레이블 인코더를 사용해 0과 1로 변환한다. LabelEncoder의 fit_transform 메서드를 사용해 간단히 숫자로 변환한다.
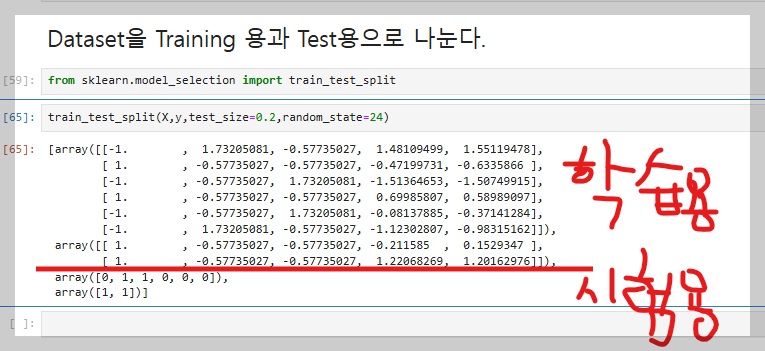
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=24)
X_train,X_test,y_train,y_test <=변수명이렇게 쓰는게 국룰
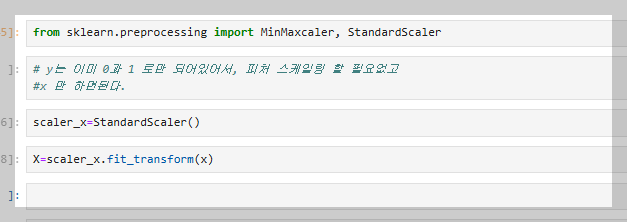
숫자로 변환한 데이터를 그대로 사용하면 데이터의 스케일이 크거나 불균형할 수 있으므로, **피처 스케일링(feature scaling)**을 통해 데이터를 일정 범위로 변환해야 한다. 이를 위해 MinMaxScaler(최소값과 최대값을 기준으로 변환)나 StandardScaler(평균 0, 표준편차 1로 변환)를 사용한다. 예제에서는 StandardScaler를 사용하여 X 데이터를 변환한다.
데이터 준비가 완료되면 학습 모델의 성능 평가를 위해 데이터를 학습용(Train)과 테스트용(Test)으로 나눈다. 학습용 데이터는 인공지능 모델이 구매 여부를 학습하도록 가르치는 데 사용하고, 테스트용 데이터는 학습 후 숨겨둔 데이터를 통해 모델이 얼마나 정확하게 예측하는지 평가한다. 데이터 분리는 train_test_split 함수를 사용하며, 학습 데이터와 테스트 데이터의 비율은 일반적으로 8:2 또는 7:3으로 설정한다.
모델 학습 후 테스트 데이터를 활용해 예측을 수행하고, 실제 정답과 비교하여 정확도를 측정한다. 이 과정에서 모델이 얼마나 잘 학습했는지 확인할 수 있다. 만약 테스트 정확도가 낮다면 모델의 개선이 필요하며, 이후 충분한 성능이 확보되었을 때 실제 서비스에 적용한다. 이 과정을 거치지 않으면 예측 결과가 부정확하거나 엉뚱한 결과를 생성할 위험이 있다.
'Python > 실습' 카테고리의 다른 글
| 파이썬: 수익 예측 인공지능 만들기 (1) | 2025.01.27 |
|---|---|
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |
| 파이썬 : 차트 (0) | 2025.01.24 |
| 파이썬 : 판다스 데이터 연결 (0) | 2025.01.23 |
| 파이썬: 판다스를 활용한 문자열 데이터 가공 (0) | 2025.01.22 |