
1. 비어있는지 확인

2. 엑스 와이 변수 저장하기

3. 문자가 있는지 확인후 있으면 형태변환
문자열 데이터(범주형 변수)는 원-핫 인코딩을 통해 숫자 형태로 변환하며, ColumnTransformer를 사용하면 특정 열만 변환하고 나머지 열은 유지할 수 있다.
변환 결과는 원-핫 인코딩된 열이 왼쪽에, 변환되지 않은 열은 오른쪽에 위치하게 된다.
변환된 데이터는 다시 원본 변수에 저장하여 이후 모델 학습에 활용한다.

4. train & test 분리

5-1. 리니어 방법 인공지능 만든후 학습시키기
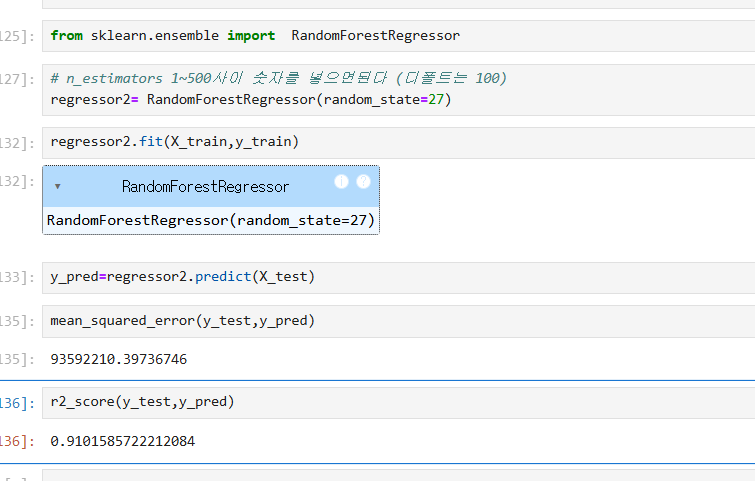

5-2. 랜덤포레스트리그레서 (Random Forest Regressor) 로 만들고 학습시키기
랜덤 포레스트 회귀(Random Forest Regressor)는 여러 개의 결정 트리를 만들어 예측 결과를 평균내어 최종 결과를 도출하는 알고리즘이다.
이 알고리즘은 데이터 특성과 하이퍼파라미터 설정에 따라 성능이 달라지므로, 트리의 개수(n_estimators)나 트리의 최대 깊이(max_depth) 같은 설정을 바꿔가며 실험적으로 최적의 값을 찾아야 한다.
각 데이터셋마다 적합한 설정이 다르기 때문에, 다양한 설정을 시도하며 최적의 모델을 만드는 과정이 중요하다.

6. 시험보기
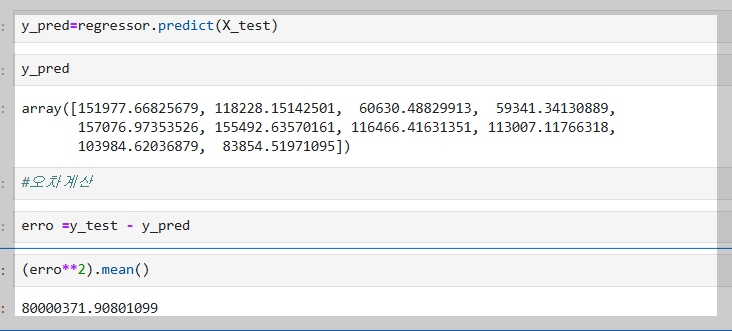
7. 오차 계산(시험채점)
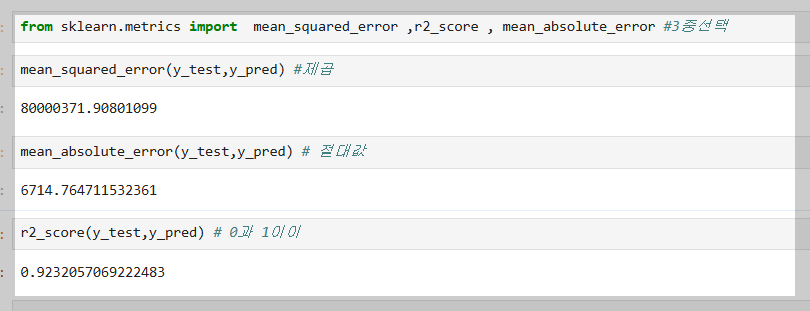
7-1 오차계산 라이브러리
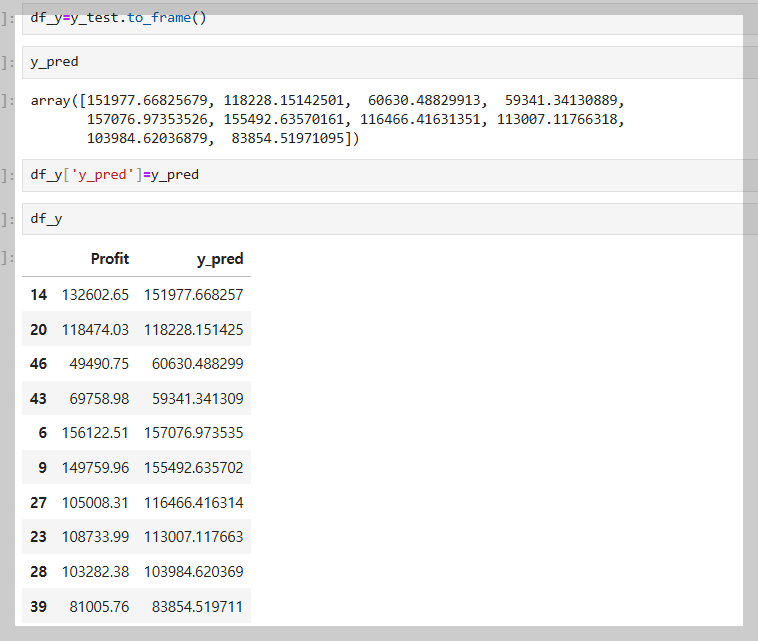
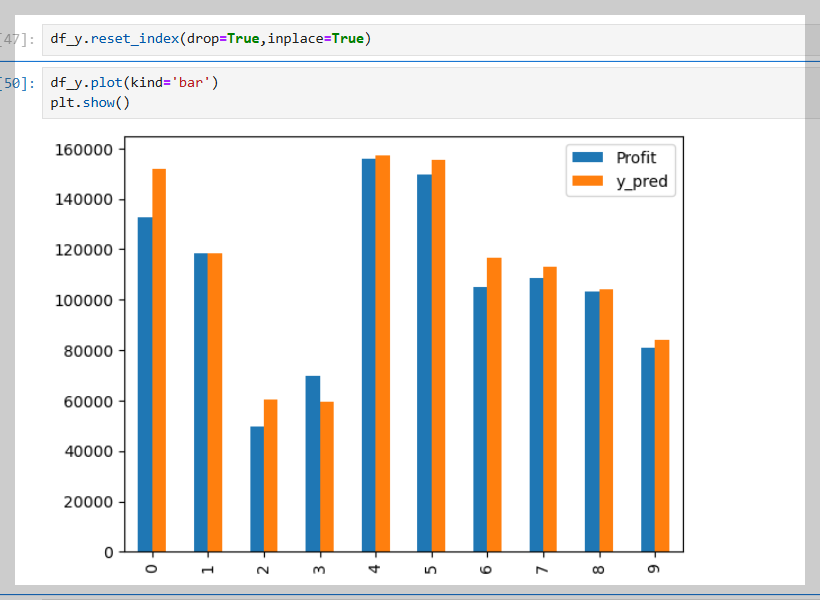
8. 그래프로 오차 수치 보기 편하게 보기
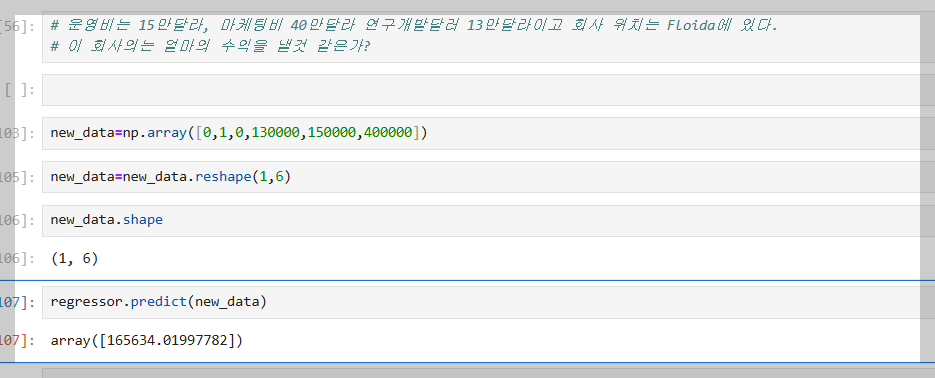
9. 새로운 데이터 넣어 보기
새로운 데이터를 만들 때는 테스트 데이터를 참고해서 작성하면 된다.
np.array를 이용해 데이터를 작성하며, 이때 학습시킨 데이터 형식에 맞춰 작성해야 한다. 학습 시에 인코딩된 문자열 부분은 해당 자리에 1을, 그렇지 않은 자리는 0을 넣어준다.
인코딩된 값은 보통 가장 왼쪽에 오기 때문에, 왼쪽부터 순서대로 해당 언어의 자리를 표시하고 나머지 자리에는 순서에 맞는 값을 입력한다.
또한, 학습 시 입력 데이터를 2차원 배열로 사용했기 때문에, 새로 만든 데이터 역시 2차원 배열로 만들어야 한다. 이를 위해 reshape를 사용해 2차원 배열로 변환한 후 데이터를 입력하면 된다.
인공지능은 학습할 때 사용한 데이터의 모양(구조)을 기억하기 때문에, 입력 데이터도 반드시 같은 모양에 맞춰 입력해야 정상적으로 작동한다.
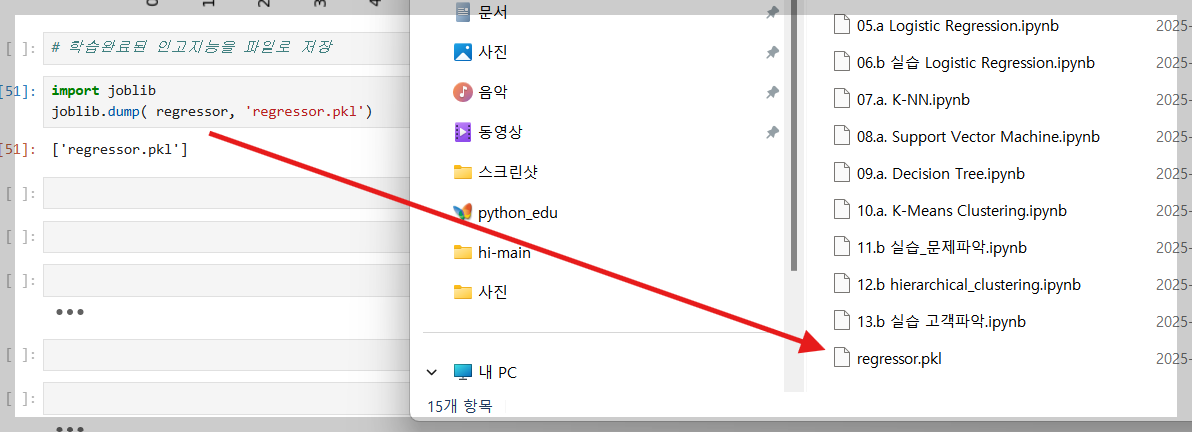
10. 인공지능이 좋다 이거 서비스화 하자! 했을 경우 파일만들기
'Python > 실습' 카테고리의 다른 글
| 서포트 벡터 머신(SVM) 실습: 분류와 정확도 분석 (0) | 2025.01.31 |
|---|---|
| 파이썬 : K-Nearest Neighbor (0) | 2025.01.29 |
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |
| 파이썬 : 머신러닝, 데이터 프리프로세싱 (3) | 2025.01.24 |
| 파이썬 : 차트 (0) | 2025.01.24 |