
서포트 벡터 머신(Support Vector Machine, SVM)의 작동 원리는 다음과 같다.
주어진 데이터에서 X축은 난이도, Y축은 급여(salary)로 설정하며, 구매한 사람은 녹색, 구매하지 않은 사람은 빨간색으로 표시한다고 가정한다. 기존 데이터가 4천만 개 이상 있다면, 모든 데이터가 이 좌표상에 분포할 것이다. 새로운 데이터가 들어오면, 우리는 기존 데이터를 바탕으로 해당 데이터가 구매할 가능성이 높은지(녹색) 아니면 구매하지 않을 가능성이 높은지(빨간색) 예측할 수 있다.
SVM은 이러한 예측을 수행하는 모델 중 하나이다. 새로운 데이터가 들어왔을 때, 그 데이터가 기존 데이터 중 어느 쪽(구매함/구매하지 않음)에 가까운지를 판단하여 예측을 수행한다. 만약 명확하게 구분되는 영역에 속한다면 쉽게 예측할 수 있지만, 중간 지점에 위치한 경우에는 애매할 수 있다. 이러한 애매한 부분에서 SVM은 데이터를 가장 잘 구분할 수 있는 결정 경계를 학습하여 예측을 수행한다.
즉, SVM은 주어진 데이터에서 최적의 분류 경계를 찾아 새로운 데이터가 어느 범주에 속할지를 판단하는 역할을 한다.
서포트 벡터 머신(Support Vector Machine, SVM)의 개념을 사과와 오렌지를 예로 들어 설명할 수 있다.
사과와 오렌지는 일반적으로 쉽게 구분할 수 있지만, 일부 모양이나 색이 비슷한 경우에는 경계에 위치할 가능성이 있다. 이러한 데이터를 수치화하여 표현하면, 명확히 구분되는 데이터는 각각의 그룹에 속하지만, 경계에 위치한 데이터는 분류하기 애매할 수 있다.
SVM은 이러한 애매한 데이터를 고려하여 최적의 경계선을 찾는다. 이때, 결정 경계(decision boundary)를 설정하는 과정에서 가장 중요한 데이터 포인트들을 서포트 벡터(support vector)라고 한다.
서포트 벡터는 데이터의 경계를 정의하는 역할을 하며, 이를 기반으로 최적의 분류선을 계산한다.
이 분류선은 두 그룹(사과와 오렌지)을 가장 잘 구분할 수 있도록 그려지며, 선과 가장 가까운 서포트 벡터와의 거리를 최대화하는 방향으로 결정된다. 이후 새로운 데이터가 들어오면, 이 경계를 기준으로 해당 데이터가 사과인지 오렌지인지 예측할 수 있다.
즉, SVM 알고리즘은 데이터 간의 경계를 찾아 선을 긋고, 이를 기준으로 새로운 데이터를 분류하는 방식으로 작동한다.
광고를 보고 구매했는지 여부에 대한 데이터를 분석할 때, 먼저 데이터가 비어 있는지 확인한다. 이후 X축과 Y축을 설정하여 분석을 진행한다.
또한, 데이터에 문자열이 포함되어 있는지 확인하지만, 해당 데이터가 숫자로 이루어져 있기 때문에 문자열 처리는 필요하지 않다. 대신, 데이터의 크기 차이를 조정하기 위해 스케일링(scaling)을 적용한다. 이를 통해 각 변수의 값 범위를 일정하게 맞추어 모델의 성능을 향상시킨다.
이제 모델을 학습시킬 단계이다.
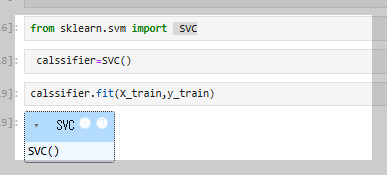
주어진 문제는 지도 학습(Supervised Learning)에 해당하므로, 학습할 때 X_train과 y_train 데이터를 사용하여 정답과 함께 학습을 진행한다. 이를 통해 모델이 주어진 입력(X)과 정답(y)의 관계를 학습하게 된다.
이 과정에서 fit 메서드에 데이터를 넣어주면 모델이 학습을 수행하며, 이를 통해 분류 알고리즘이 만들어진다.
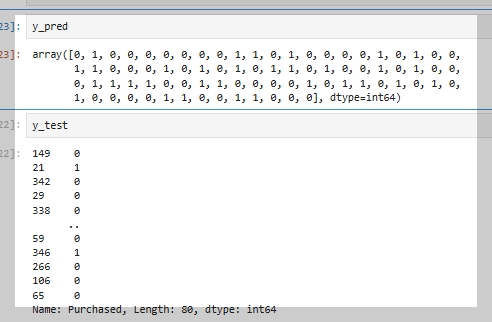
학습이 완료된 후에는 모델의 성능을 평가하기 위해 테스트 데이터를 활용하여 예측을 수행한다.
예측 결과가 정확한지 하나하나 확인하는 것은 비효율적이므로, 한눈에 결과를 확인하려면 score 또는 accuracy_score와 같은 평가 지표를 활용하면 된다.

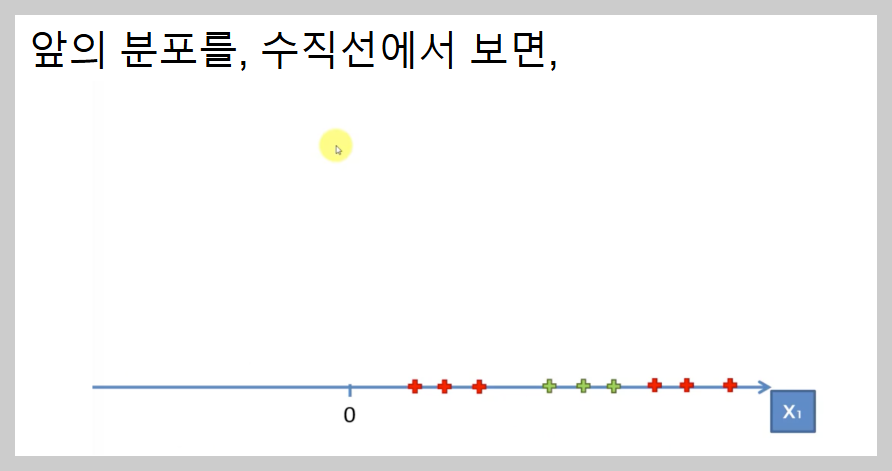
서포트 벡터 머신(SVM)은 선형적으로 분리 가능한 데이터와 분리 불가능한 데이터를 처리하는 방식이 다르다.
만약 데이터가 선형적으로 구분 가능하다면, 하나의 직선(또는 초평면)으로 데이터를 명확하게 나눌 수 있다. 이러한 경우를 선형적으로 분리 가능(Linear Separable)하다고 한다.
하지만 일부 데이터는 단순한 선으로 구분할 수 없는 경우가 있다. 이를 비선형적으로 분리 불가능(Not Linearly Separable)한 데이터라고 하며, 이때는 커널 트릭(Kernel Trick)을 사용하여 데이터를 고차원 공간으로 변환한다.
즉, 기존의 2차원 공간에서는 선으로 구분할 수 없더라도, 차원을 증가시키면 구분이 가능해진다. 이러한 방식으로 복잡한 패턴을 학습할 수 있도록 돕는 것이 SVM의 핵심 개념 중 하나이다.
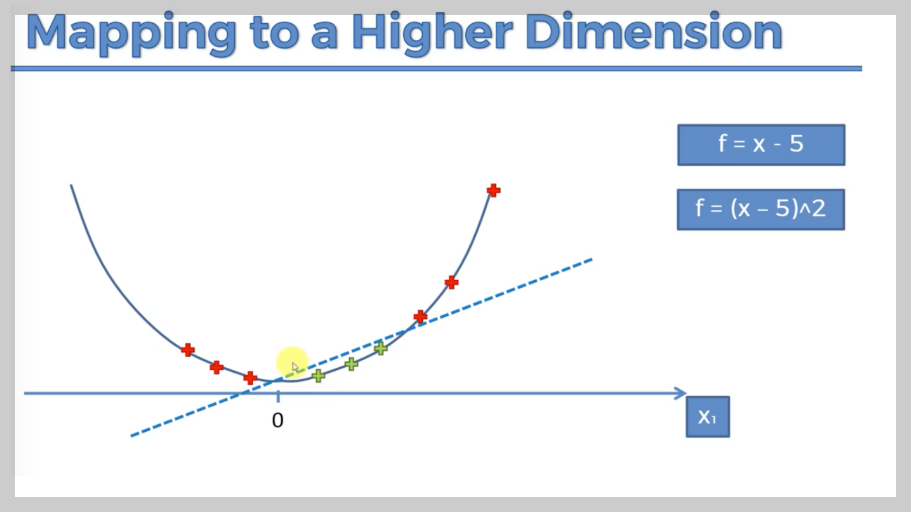
비선형적으로 구분되지 않는 데이터도 고차원 공간으로 변환하면 쉽게 분류할 수 있다.
1차원에서는 선형적으로 구분이 어렵지만, 특정 변환을 적용해 2차원 이상으로 바꾸면 선이나 곡선으로 분리할 수 있다. SVM은 커널 트릭을 사용해 이런 변환을 자동으로 수행한다.
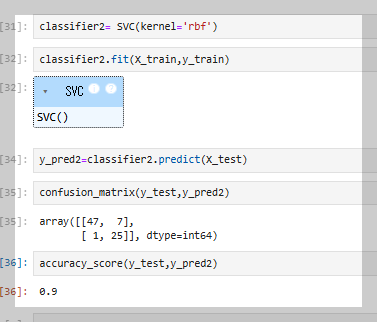
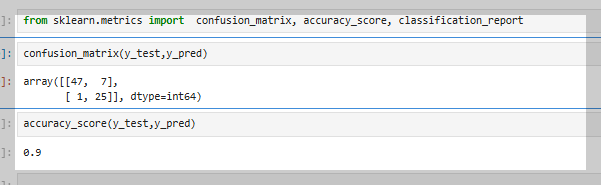
SVM 분류기를 RBF 커널로 학습시켜 테스트 데이터를 예측하고, 혼동 행렬을 확인한 후 정확도를 계산하였다
'Python > 실습' 카테고리의 다른 글
| 파이썬 : K-Means Clustering,Hierarchical Clustering (0) | 2025.01.31 |
|---|---|
| 파이썬 : Decision Tree (0) | 2025.01.31 |
| 파이썬 : K-Nearest Neighbor (0) | 2025.01.29 |
| 파이썬: 수익 예측 인공지능 만들기 (1) | 2025.01.27 |
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |