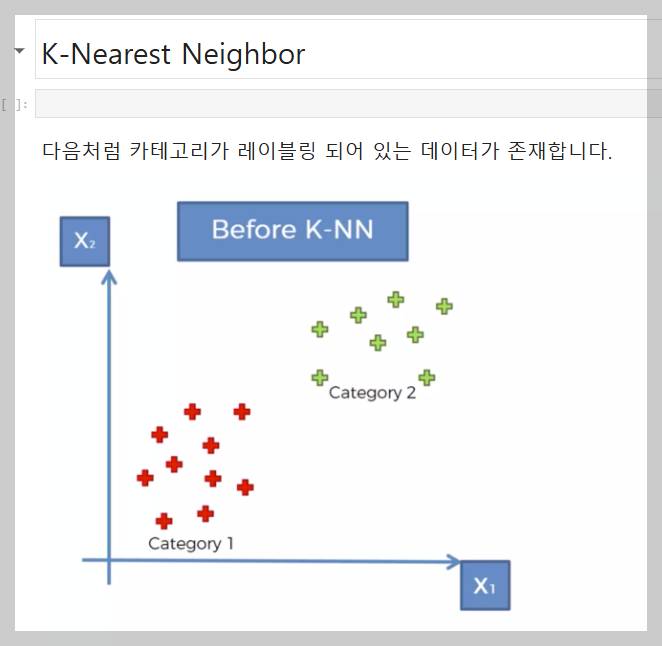

K-Nearest Neighbor(KNN) 알고리즘은 새로운 데이터 포인트를 분류할 때,
기존 데이터 중 가장 가까운 K개의 이웃을 참고하여 분류를 결정하는 지도 학습 방법이다. KNN은 주로 거리 기반 계산을 통해 데이터 간 유사성을 측정하며, 자주 사용하는 거리 척도로는 유클리드 거리가 있다.
- 새로운 데이터 포인트와 기존 데이터 간의 거리를 계산한다.
- 가장 가까운 K개의 이웃을 선택한다.
- 선택된 이웃들의 다수결 또는 평균을 기반으로 결과를 예측한다.
KNN은 구현이 간단하고 이해하기 쉬우며, 분류와 회귀 문제 모두에 사용할 수 있다는 장점이 있다. 그러나 데이터 크기가 크거나 차원이 높은 경우 계산 비용이 증가할 수 있어 적절한 데이터 전처리와 K 값 선택이 중요하다.

1. 결측치 확인

2. 필요데이터 X,y 변수저장

3. 스케일링하기

4. train/test
train_test_split 함수를 사용하여 데이터를 학습용(X_train, y_train)과 테스트용(X_test, y_test)으로 분리한다. test_size=0.2는 테스트 데이터 비율을 20%로 설정하고, random_state=27은 데이터 분할의 재현성을 보장한다.

5. KNeighborsClassifier를 이용하여 KNN 분류기를 생성한다.
n_neighbors=5는 K값을 5로 설정하여, 새로운 데이터 포인트를 분류할 때 가장 가까운 5개의 이웃을 기준으로 결정한다.
from sklearn.neighbors import KNeighborsClassifier

6. 학습시키기
from sklearn.metrics import confusion_matrix,accuracy_score,classification_report
7.채점
- 컨퓨전 매트릭스 계산: confusion_matrix를 사용하여 y_test와 pred_y 간의 컨퓨전 매트릭스를 계산한다. 결과는 [[48, 6], [3, 23]]로, 올바른 예측(48, 23)과 잘못된 예측(6, 3)을 보여준다.
- 정확도 계산: accuracy_score를 사용하여 모델의 정확도를 계산한다. 정확도는 0.8875(88.75%)로 나타난다.
- 분류 리포트 출력: classification_report를 사용하여 정밀도(precision), 재현율(recall), F1 점수(f1-score), 그리고 각 클래스의 데이터 개수를 출력한다.
- 클래스 0의 정밀도는 0.94, 재현율은 0.89.
- 클래스 1의 정밀도는 0.79, 재현율은 0.88.
- 전체 정확도는 0.89로 출력된다.

8. 그래프로 확인

9. 신규데이터
- 새로운 데이터 생성:
- np.array([37, 37500])를 통해 새로운 데이터를 생성한다.
- 데이터를 모델에 입력하기 위해 reshape(1, 2)로 2차원 배열로 변환한다.
- 스케일링:
- scaler_X.transform(new_data)를 사용하여 새로운 데이터를 기존 학습 데이터와 동일한 스케일로 변환한다.
- 경고 메시지는 데이터에 feature names가 없음을 알리는 것으로, 모델 작동에는 영향을 미치지 않는다.
- 예측 수행:
- classifier.predict(new_data)를 통해 새로운 데이터에 대한 예측을 수행한다.
- 결과값은 [0]으로, 새로운 데이터가 클래스 0으로 분류되었음을 의미한다.
'Python > 실습' 카테고리의 다른 글
| 파이썬 : Decision Tree (0) | 2025.01.31 |
|---|---|
| 서포트 벡터 머신(SVM) 실습: 분류와 정확도 분석 (0) | 2025.01.31 |
| 파이썬: 수익 예측 인공지능 만들기 (1) | 2025.01.27 |
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |
| 파이썬 : 머신러닝, 데이터 프리프로세싱 (3) | 2025.01.24 |