Decision Tree


디시전 트리(Decision Tree)는 데이터를 분류하거나 예측할 때 사용되는 모델이며, 랜덤 포레스트(Random Forest)는 이를 개선한 알고리즘이다.
디시전 트리는 비선형적인(Non-linear) 데이터를 다룰 수 있으며, 데이터를 여러 기준으로 나누어 의사 결정을 수행한다. 예를 들어, 특정 기준(예: 60보다 큰 값과 작은 값)을 기준으로 데이터를 두 그룹으로 나누고, 이후 다시 X축을 기준으로 세분화하여 나눈다.
이 과정은 반복적으로 진행되며, 데이터가 점점 세밀하게 분류된다. 하지만 너무 많은 기준을 설정하면 복잡한 모델이 만들어질 수 있으므로, 적절한 깊이(depth)나 가지치기(pruning) 기법을 사용하여 과적합을 방지하는 것이 중요하다.
이러한 분할 기준과 트리의 깊이는 우리가 직접 설정할 수 있으며, 이를 조정하여 모델의 성능을 최적화할 수 있다.

이처럼 데이터를 반복적으로 쪼개는 방식이 트리(Tree) 구조이다. 트리 구조는 위에서 아래로 내려가며 데이터를 분류하는데, 이를 뒤집어 보면 나무처럼 보이기 때문에 이러한 명칭이 붙었다.
새로운 데이터(신규 데이터)가 들어오면, 기존 트리 구조를 따라 분류가 진행된다. 먼저 첫 번째 기준(스플릿)을 기준으로 데이터가 큰지 작은지를 판단하고, 이후 해당 그룹에서 다시 두 번째 스플릿 기준을 적용한다. 예를 들어, 특정 값이 70보다 큰지 작은지를 확인한 후, 그 결과에 따라 왼쪽 또는 오른쪽으로 이동하며 최종적으로 해당 데이터가 속할 범주를 결정한다.
이러한 방식으로 데이터를 단계적으로 분류하는 것이 디시전 트리의 기본 원리이다.


있는지 없는 지확인 후 엑스와이를 설정해주고 스케일링을 통해 범위를 맞춰준다


디시전 트리(Decision Tree) 분류기를 사용하여 데이터를 학습하고 평가하는 과정을 보여준다.
먼저, train_test_split을 이용해 데이터를 훈련용(X_train, y_train)과 테스트용(X_test, y_test)으로 8:2 비율로 나눈다.
그런 다음, DecisionTreeClassifier(random_state=27)을 생성하고 fit(X_train, y_train)을 실행하여 모델을 학습한다.
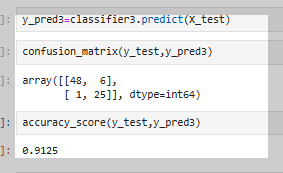
모델이 학습된 후 predict(X_test)를 사용해 테스트 데이터를 예측하고, confusion_matrix(y_test, y_pred)를 통해 실제값과 예측값의 차이를 확인한다.
마지막으로, accuracy_score(y_test, y_pred)를 활용해 모델의 정확도를 계산하며, 결과는 약 88.75%로 나타난다.
즉, 디시전 트리를 활용한 머신러닝 분류 모델을 구축하고 성능을 평가하는 과정이다
다른 인공지능과 비교
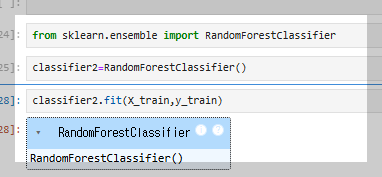
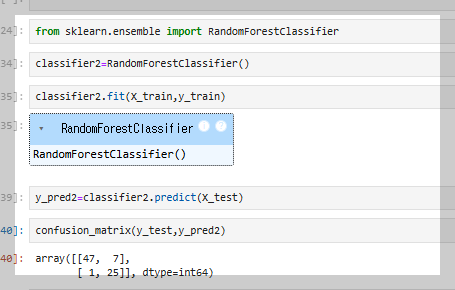
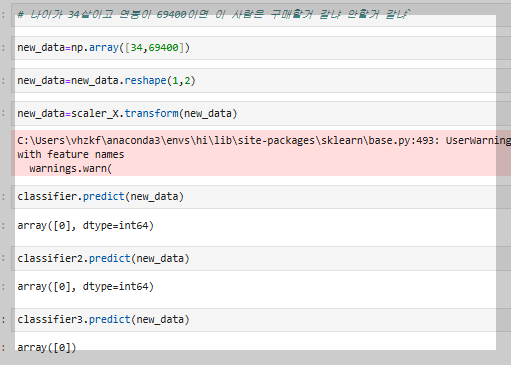
인공지능 모델의 성능은 데이터의 특성과 문제 유형에 따라 달라지므로, 절대적으로 가장 좋은 모델은 존재하지 않는다.
예를 들어, 작은 데이터셋에서는 디시전 트리(Decision Tree)나 로지스틱 회귀(Logistic Regression)가 효과적일 수 있지만, 대규모 데이터에서는 랜덤 포레스트(Random Forest)나 XGBoost가 더 나은 성능을 낼 수 있다.
또한, 이미지나 자연어 처리 같은 복잡한 문제에서는 딥러닝 모델(CNN, RNN, Transformer 등)이 적합하다.
따라서 최적의 모델을 찾기 위해서는 데이터 분석, 모델 실험(하이퍼파라미터 튜닝 포함), 그리고 성능 평가(정확도, F1-score 등)를 반복적으로 수행하는 과정이 필요하다.
'Python > 실습' 카테고리의 다른 글
| 파이썬 : K-Means Clustering,Hierarchical Clustering (0) | 2025.01.31 |
|---|---|
| 서포트 벡터 머신(SVM) 실습: 분류와 정확도 분석 (0) | 2025.01.31 |
| 파이썬 : K-Nearest Neighbor (0) | 2025.01.29 |
| 파이썬: 수익 예측 인공지능 만들기 (1) | 2025.01.27 |
| 경력과 연봉 관계 분석 하는 인공지능 만들기 (0) | 2025.01.24 |